Module 1.6
Which Visualization Do I Use?
- Create a QMD file in your Module 1 project folder for this lesson.
- Load the necessary packages in your setup code chunk, including
readr,dplyrandggplot2. - You are also free to try loading the
tidyversethis time instead of loading the individual packages, but try to remember which packages we are actually using.
Overview
In the last lesson, we learned how to make bar (column) charts and historgrams. In this lesson we are going to be learning how to make two more types of visualizations that we can create with ggplot2–line charts and scatter plots. We will also delve into some more advanced topics with respect to scatter plots including adding trend lines, facet wrapping and labeling points.
Line charts
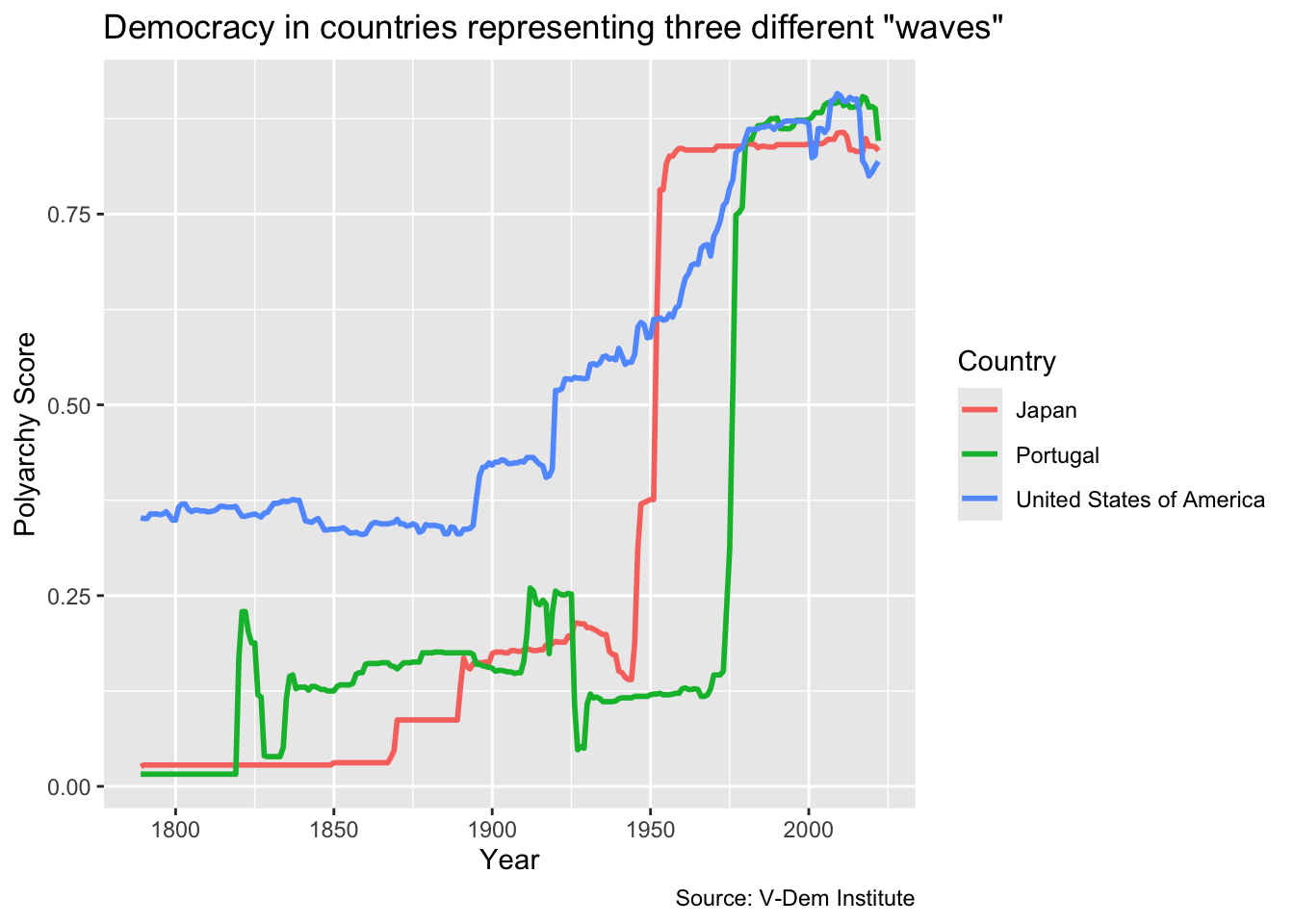
Let’s create a line chart. For this visualization, we will try to illustrate Samuel Huntington’s waves of democracy by showing how countries representing each of the three waves. The U.S. represents the first wave, Japan the second wave starting with the allied victory in WWII, and Portugal represents the first country to transition in the third wave.
First, let’s grab the relevant data. We are going to be downloading the polyarchy measure for the U.S., Japan and Portugal as far back as the data are available. These are already wrangled and saved for you in an object called dem_waves_ctrs.
Let’s go ahead and download those, save them in the data subfolder for this module and read them into R.
dem_waves_ctrs <- read_csv("data/dem_waves_ctrs.csv")Next, we are going to do our ggplot() call. The data will be the dem_waves_ctrs object that we just created. For the aesthetics mapping, we will put the year on the x-axis and the polyarchy score on the y-axis. We will also specify color in the aes() call so that we can color the lines by region.
To get a line chart, we have to specify geom_line(). Then within the geom_line() function we will set the linewidth equal to `1’ so that the lines are a bit more visible.
Finally, we will add a labs() call as with the previous visualizations. But in addition to title, axis labels and a caption, we will also add color = "Country" to change the label of the legend to “Country” with a capital “C.”
# in this ggplot() call, we add a third dimension for line color
ggplot(dem_waves_ctrs, aes(x = year, y = polyarchy, color = country)) +
geom_line(linewidth = 1) + # our geom is a line with a width of 1
labs(
x = "Year",
y = "Polyarchy Score",
title = 'Democracy in countries representing three different "waves"',
caption = "Source: V-Dem Institute",
color = "Country" # make title of legend to upper case
)
Scatter plots
The last visualization we are going to cover is a scatter plot. In this example, we are going to illustrating modernization theory, which predicts a positive relationship between wealth and democracy, while also incorporating levels of women’s representation into our analysis.
We are going to start with the dem_women.csv file we used in the last module. We will then group the data by country and calculate the mean for each variable. In the group_by() call we also include region because we will want to keep it so that we can color our points by region.
Grouping and summarizing variables will be covered more in a future module, but here just know that we are doing this to get the average of each variable for each country. Another option could be to filter the data for one year, as we did for the histogram in the last module.
Now let’s create our first scatter plot. Our ggplot() call looks similar to previous ones except for a few things. First we are calling geom_point() for our geom. But also notice that our aesthetics mapping includes four dimenstions: x, y, color and size. So here we are telling ggplot2 that we want wealth on the x-axis, the polyarchy score on the y-axis, to color the points based on region, and to vary the size of the points in relation to the level of women’s representation.
One last thing we want to do is to put our x-axis on a log scale and change the labels to reflect their dollar values. For the log scale, we can use the scale_x_log10() function and for the labels we can use the label_number() function from the scales package. We set the prefix to “$” and the suffix to “k” so that each number on the x-axis starts with a dollar sign and ends with “k” denoting “thousands.”
We will encounter other useful scales functions including label_dollar() and label_percent() in future lessons.
Notice that in this example we introduce the scales package by including it as a prefix to the label_number() function, e.g. scales::label_number(prefix = "$", suffix = "k"). This allows us to use the package without having to load it, e.g. library(scales). It also has the benefit of generating a list of auto-complete suggestions for the many available functions in the scales package.
# in this ggplot() call we have four dimensions
# x, y, color, and size
ggplot(dem_summary_ctry, aes(x = gdp_pc, y = polyarchy, color = region, size = women_rep)) +
geom_point() + # use geom_point() for scatter plots
scale_x_log10(labels = scales::label_number(prefix = "$", suffix = "k")) +
labs(
x= "GDP per Capita",
y = "Polyarchy Score",
title = "Wealth and democracy, 1990 - present",
caption = "Source: V-Dem Institute",
color = "Region",
size = "Women Reps"
)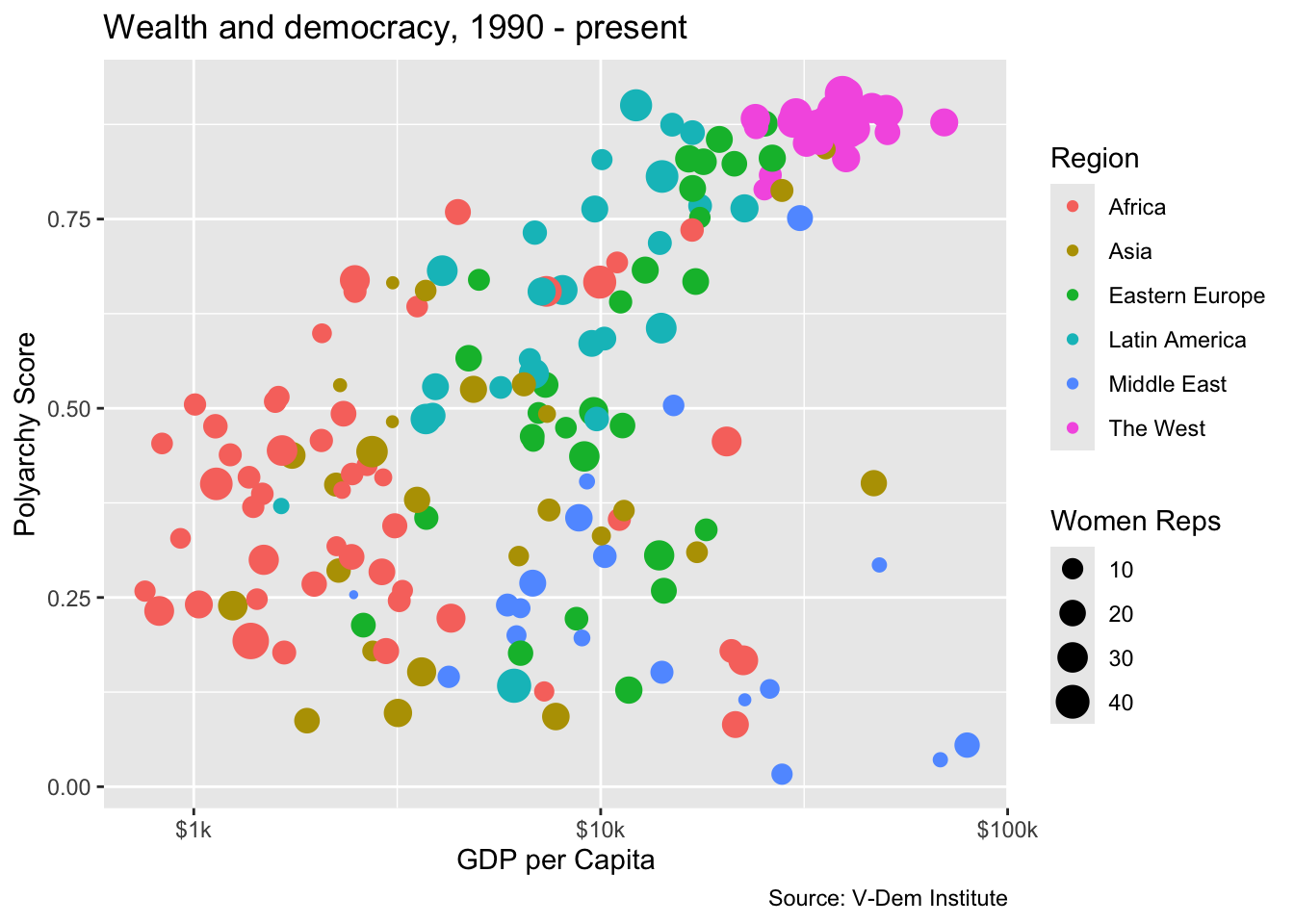
The plot does a good job of illustrating the basic point of modernization theory in that we do see the positive correlation between wealth and democracy. But we also see that there are some outliers and that a lot of the outlier countries are concentrated in the Middle East.
We also see that the distribution of women’s representation is somewhat orthogonal to wealth and democracy. Most wealthy western countries have high levels of women’s representation, but so do a lot of low- and middle-income countries in Africa, Asia and Latin America.
Adding a trend line
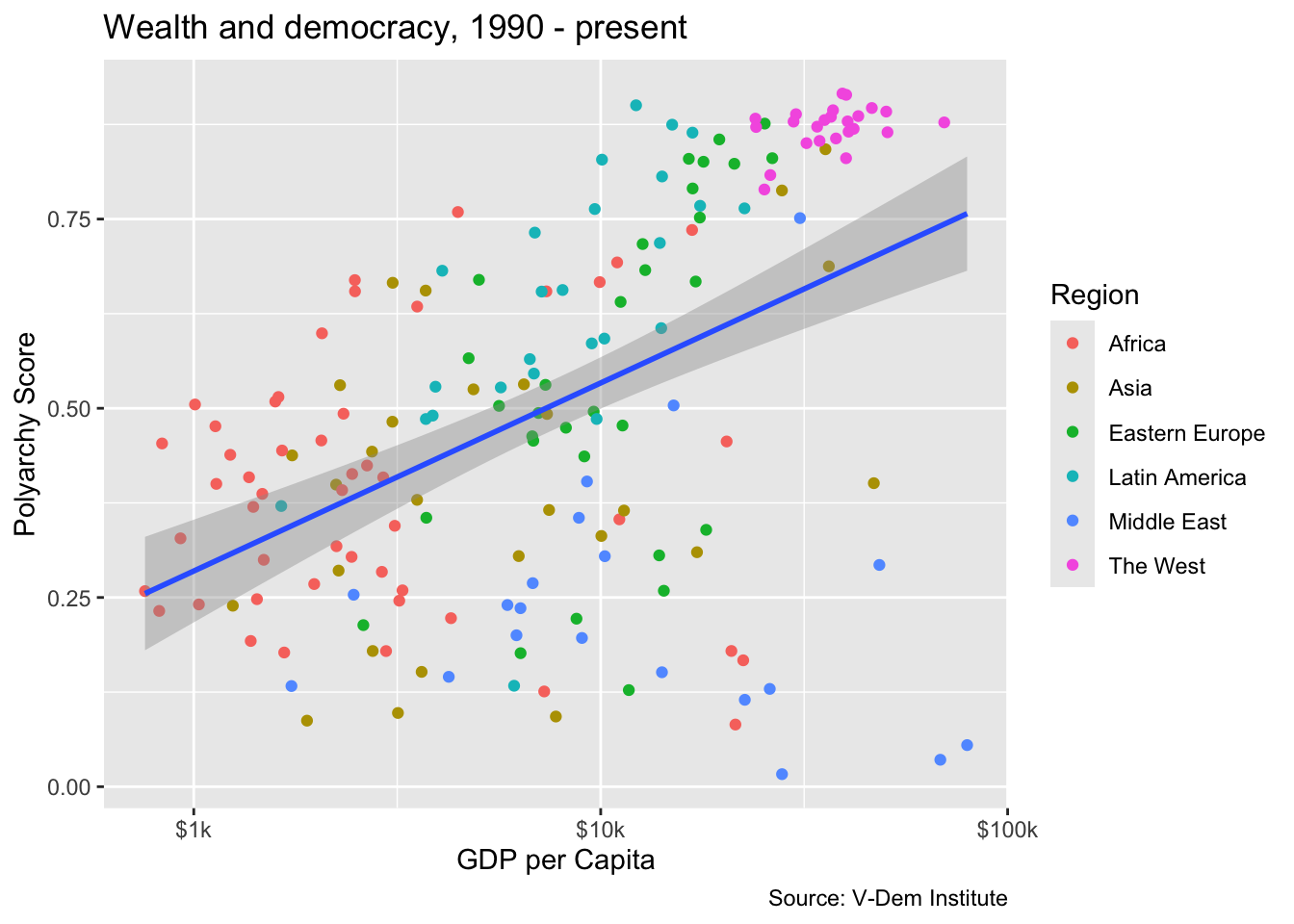
We can definitely see a relationship between wealth and democracy in the scatter plot, but how strong is it? One way to find out is to add a trend line. Let’s do this by adding another geom, geom_smooth(), and specifying a linear model with the argument method = "lm" We acn also set the linewidth of the trend line to 1 so that the line is more visible.
If we want to add a single trend while also maintaining the coloring by region, then we have to reconfigure the ggplot() call a bit. Specifically, we will want to move color = region to a separate aes() call in the geom_point() function, e.g. geom_point(aes(color = region)). If we don’t do this we will get separate trend lines for each region (try it and see!).
ggplot(dem_summary_ctry, aes(x = gdp_pc, y = polyarchy)) +
geom_point(aes(color = region)) +
geom_smooth(method = "lm", linewidth = 1) +
scale_x_log10(labels = scales::label_number(prefix = "$", suffix = "k")) +
labs(
x= "GDP per Capita",
y = "Polyarchy Score",
title = "Wealth and democracy, 1990 - present",
caption = "Source: V-Dem Institute",
color = "Region"
)
Facet wrapping
Now let’s imagine that we really interested in drilling down into the “heterogeneous effects” of wealth on democracy by region. In other words, we want to see more clearly how wealth is related to democracy in some regions but not others. For this, we can use facet_wrap() to get a separate chart for each region rather than just shading the points by region. Inside of facet_wrap() we identify region as the variable that we want to use to separate the plots, e.g. facet_wrap(~region). Notice how we have to include a tilde (~) here.
ggplot(dem_summary_ctry, aes(x = gdp_pc, y = polyarchy)) +
geom_point() +
geom_smooth(method = "lm", linewidth = 1) +
facet_wrap(~ region) +
scale_x_log10(labels = scales::label_number(prefix = "$", suffix = "k")) +
labs(
x= "GDP per Capita",
y = "Polyarchy Score",
title = "Wealth and democracy, 1990 - present",
caption = "Source: V-Dem Institute"
)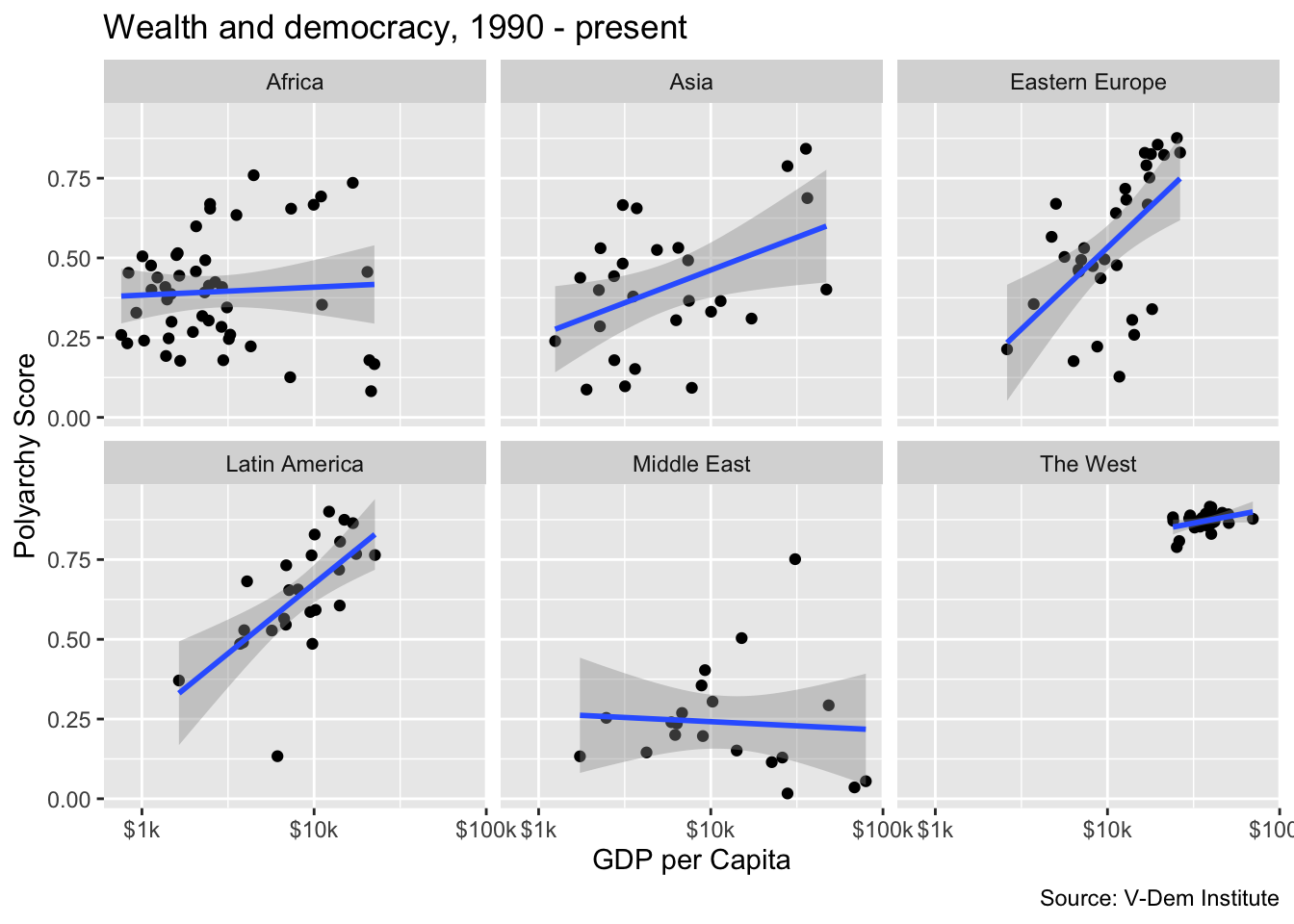
Here we can clearly see a relationship between wealth and democracy in all of the countries except for the Middle East and Africa. We could speculate that the lack of a relationship in the Middle East could be evidence of an oil curse dynamic whereas perhaps the lack of a relationship in Africa is due to weak institutions.
The relationship between wealth and democracy in the West would be apparent, but it is obscured by the fact that western countries because the high wealth and polyarchy values result in extreme bunching in the northwest quadrant of the graph. To deal with this issue, we could add the scales = "free" argument to our plot.
ggplot(dem_summary_ctry, aes(x = gdp_pc, y = polyarchy)) +
geom_point() +
geom_smooth(method = "lm", linewidth = 1) +
facet_wrap(~ region, scales = "free") +
scale_x_log10(labels = scales::label_number(prefix = "$", suffix = "k")) +
labs(
x= "GDP per Capita",
y = "Polyarchy Score",
title = "Wealth and democracy, 1990 - present",
caption = "Source: V-Dem Institute"
)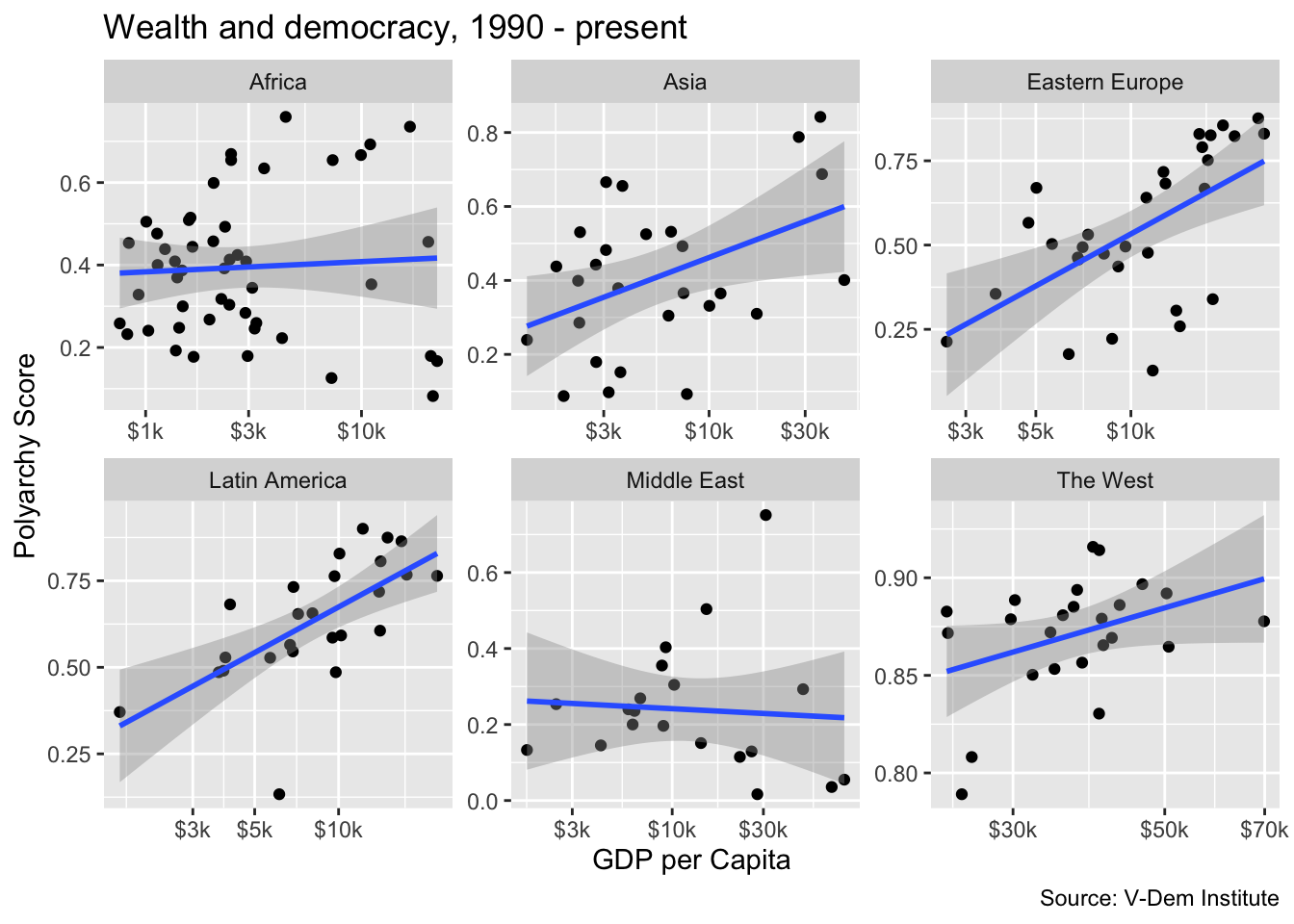
But notice there is a bit of a tradeoff here. With the scales = free option set, we now have separate axes for each of the plots. This is less of a clean look than having common x and y axes.
### Labeling points
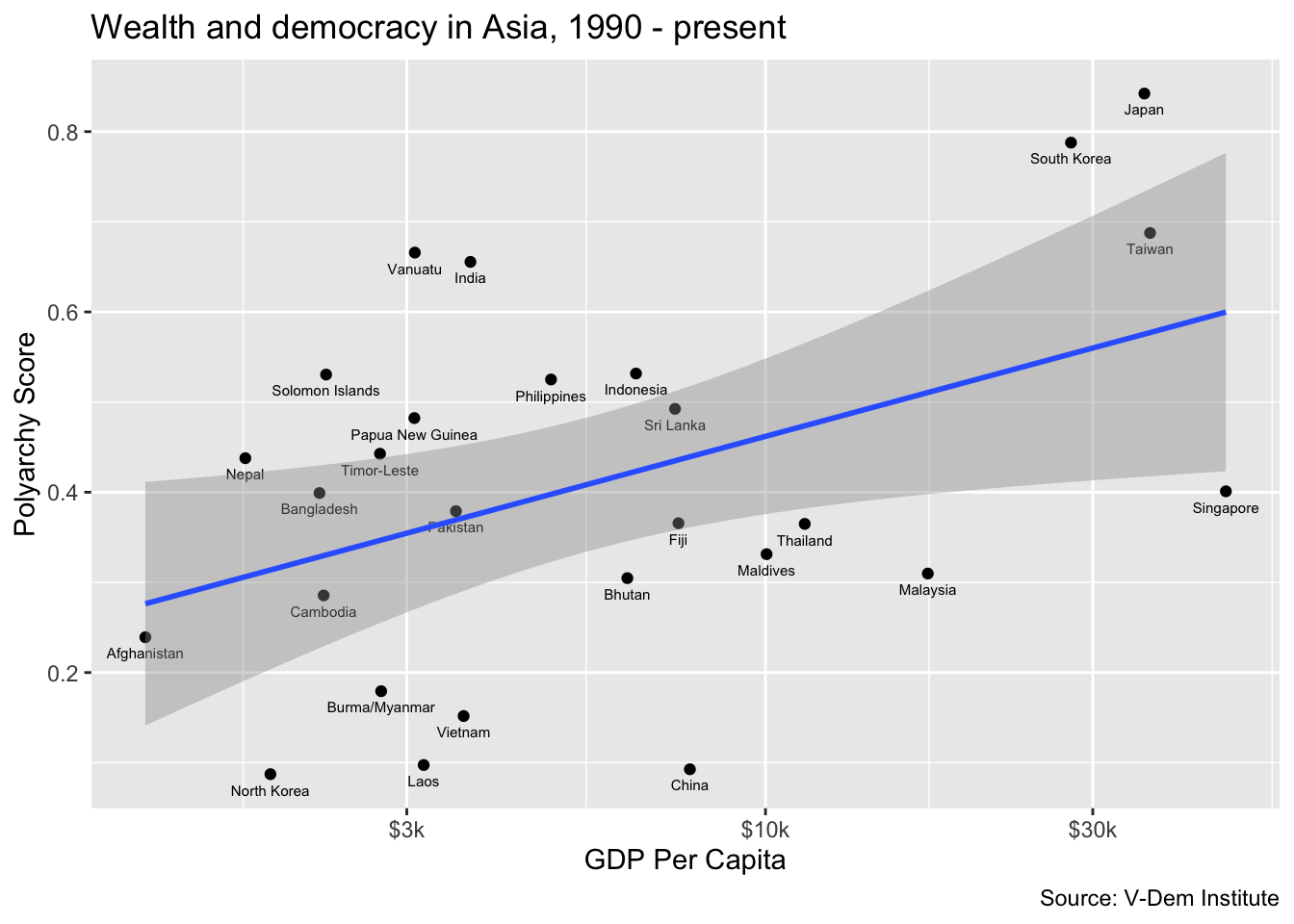
Now let’s try drilling down into one of the regions to get a better sense of what countries are driving the relationship. To do this, we can filter our data set for a region that we are interested in and then add country labels to the points in the scatter plot. Here we are going to filter for “Asia” and we will ad a geom_text() call to add country labels. In the geom_text() call we include arguments for size and vjust to adjust the size and vertical location of the labels relative to the points.
dem_summary_ctry |>
filter(region == "Asia") |>
ggplot(aes(x = gdp_pc, y = polyarchy)) +
geom_point() +
geom_text(aes(label = country), size = 2, vjust = 2) +
geom_smooth(method = "lm", linewidth = 1) +
scale_x_log10(labels = scales::label_number(prefix = "$", suffix = "k")) +
labs(
x= "GDP Per Capita",
y = "Polyarchy Score",
title = "Wealth and democracy in Asia, 1990 - present",
caption = "Source: V-Dem Institute"
)