# A tibble: 2 × 5
subject time age weight height
<chr> <dbl> <dbl> <dbl> <dbl>
1 John Smith 1 33 90 1.87
2 Mary Smith 1 NA NA 1.54Tidying Data
October 7, 2024
Tidying Data
What is Tyding Data?
- Earlier we talked about the concept of “tidy data”
- Each variable forms a column
- Each observation is in a row
- Each cell has a single value
- The process of tidying data involves reshaping (or pivoting) data into a tidy format
- We want to use the
pivot_longer()orpivot_wider()functions fromtidyrto do this
Query: Are these data in a tidy format?
Tip
To get a list of data frames available in a package use the data() function, e.g. data(package = "tidyr").
How about these data?
# A tibble: 1,064 × 20
country indicator `2000` `2001` `2002` `2003` `2004` `2005` `2006`
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 ABW SP.URB.TOTL 4.16e4 4.20e+4 4.22e+4 4.23e+4 4.23e+4 4.24e+4 4.26e+4
2 ABW SP.URB.GROW 1.66e0 9.56e-1 4.01e-1 1.97e-1 9.46e-2 1.94e-1 3.67e-1
3 ABW SP.POP.TOTL 8.91e4 9.07e+4 9.18e+4 9.27e+4 9.35e+4 9.45e+4 9.56e+4
4 ABW SP.POP.GROW 2.54e0 1.77e+0 1.19e+0 9.97e-1 9.01e-1 1.00e+0 1.18e+0
5 AFE SP.URB.TOTL 1.16e8 1.20e+8 1.24e+8 1.29e+8 1.34e+8 1.39e+8 1.44e+8
6 AFE SP.URB.GROW 3.60e0 3.66e+0 3.72e+0 3.71e+0 3.74e+0 3.81e+0 3.81e+0
7 AFE SP.POP.TOTL 4.02e8 4.12e+8 4.23e+8 4.34e+8 4.45e+8 4.57e+8 4.70e+8
8 AFE SP.POP.GROW 2.58e0 2.59e+0 2.61e+0 2.62e+0 2.64e+0 2.67e+0 2.70e+0
9 AFG SP.URB.TOTL 4.31e6 4.36e+6 4.67e+6 5.06e+6 5.30e+6 5.54e+6 5.83e+6
10 AFG SP.URB.GROW 1.86e0 1.15e+0 6.86e+0 7.95e+0 4.59e+0 4.47e+0 5.03e+0
# ℹ 1,054 more rows
# ℹ 11 more variables: `2007` <dbl>, `2008` <dbl>, `2009` <dbl>, `2010` <dbl>,
# `2011` <dbl>, `2012` <dbl>, `2013` <dbl>, `2014` <dbl>, `2015` <dbl>,
# `2016` <dbl>, `2017` <dbl>Pivot Longer
Pivot Longer
pivot_longer() takes three arguments:
- cols - which columns you want to pivot
- names_to - the name of the column where the old column names are going to (identifier)
- values_to - the name of the column where the values are going to
Example: WB Population Data
library(tidyr)
library(dplyr)
# Pivot using pivot_longer
long_pop_data <- world_bank_pop |>
pivot_longer(
cols = `2000`:`2017`, # The columns you want to pivot (years)
names_to = "year", # New column name for the years
values_to = "pop" # New column name for the values
)
# View the tidied data
long_pop_data# A tibble: 19,152 × 4
country indicator year pop
<chr> <chr> <chr> <dbl>
1 ABW SP.URB.TOTL 2000 41625
2 ABW SP.URB.TOTL 2001 42025
3 ABW SP.URB.TOTL 2002 42194
4 ABW SP.URB.TOTL 2003 42277
5 ABW SP.URB.TOTL 2004 42317
6 ABW SP.URB.TOTL 2005 42399
7 ABW SP.URB.TOTL 2006 42555
8 ABW SP.URB.TOTL 2007 42729
9 ABW SP.URB.TOTL 2008 42906
10 ABW SP.URB.TOTL 2009 43079
# ℹ 19,142 more rowsThis is better, usable even, but are we done if we want a tidy data frame?
# A tibble: 19,152 × 4
country indicator year pop
<chr> <chr> <chr> <dbl>
1 ABW SP.URB.TOTL 2000 41625
2 ABW SP.URB.TOTL 2001 42025
3 ABW SP.URB.TOTL 2002 42194
4 ABW SP.URB.TOTL 2003 42277
5 ABW SP.URB.TOTL 2004 42317
6 ABW SP.URB.TOTL 2005 42399
7 ABW SP.URB.TOTL 2006 42555
8 ABW SP.URB.TOTL 2007 42729
9 ABW SP.URB.TOTL 2008 42906
10 ABW SP.URB.TOTL 2009 43079
# ℹ 19,142 more rowsIssue is that the data are in long form (which is OK for some purposes), but we want to make it wider. Wider, but tidy…
# A tibble: 19,152 × 4
country indicator year pop
<chr> <chr> <chr> <dbl>
1 ABW SP.URB.TOTL 2000 41625
2 ABW SP.URB.TOTL 2001 42025
3 ABW SP.URB.TOTL 2002 42194
4 ABW SP.URB.TOTL 2003 42277
5 ABW SP.URB.TOTL 2004 42317
6 ABW SP.URB.TOTL 2005 42399
7 ABW SP.URB.TOTL 2006 42555
8 ABW SP.URB.TOTL 2007 42729
9 ABW SP.URB.TOTL 2008 42906
10 ABW SP.URB.TOTL 2009 43079
# ℹ 19,142 more rowsPivot Wider
Pivot Wider
pivot_wider() takes three main arguments:
- names_from - the column whose values will become new column names (identifier)
- values_from - the column containing the values that will fill the new columns
- values_fill (optional) - specifies what to use for missing values (e.g.,
NA,0)
pivotwider() the WB Data
# pivot wider
tidy_pop_data <- long_pop_data |>
pivot_wider(
names_from = indicator,
values_from = pop
)
# view the data
tidy_pop_data# A tibble: 4,788 × 6
country year SP.URB.TOTL SP.URB.GROW SP.POP.TOTL SP.POP.GROW
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 ABW 2000 41625 1.66 89101 2.54
2 ABW 2001 42025 0.956 90691 1.77
3 ABW 2002 42194 0.401 91781 1.19
4 ABW 2003 42277 0.197 92701 0.997
5 ABW 2004 42317 0.0946 93540 0.901
6 ABW 2005 42399 0.194 94483 1.00
7 ABW 2006 42555 0.367 95606 1.18
8 ABW 2007 42729 0.408 96787 1.23
9 ABW 2008 42906 0.413 97996 1.24
10 ABW 2009 43079 0.402 99212 1.23
# ℹ 4,778 more rowspivotwider() the WB Data
# A tibble: 4,788 × 6
country year SP.URB.TOTL SP.URB.GROW SP.POP.TOTL SP.POP.GROW
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 ABW 2000 41625 1.66 89101 2.54
2 ABW 2001 42025 0.956 90691 1.77
3 ABW 2002 42194 0.401 91781 1.19
4 ABW 2003 42277 0.197 92701 0.997
5 ABW 2004 42317 0.0946 93540 0.901
6 ABW 2005 42399 0.194 94483 1.00
7 ABW 2006 42555 0.367 95606 1.18
8 ABW 2007 42729 0.408 96787 1.23
9 ABW 2008 42906 0.413 97996 1.24
10 ABW 2009 43079 0.402 99212 1.23
# ℹ 4,778 more rowsExercise
Download Some Messy Data
- Download some messy WB data
- Make it multiple variables
- Download as a CSV file
- Save in your project
/datafolder
Messy Data Example
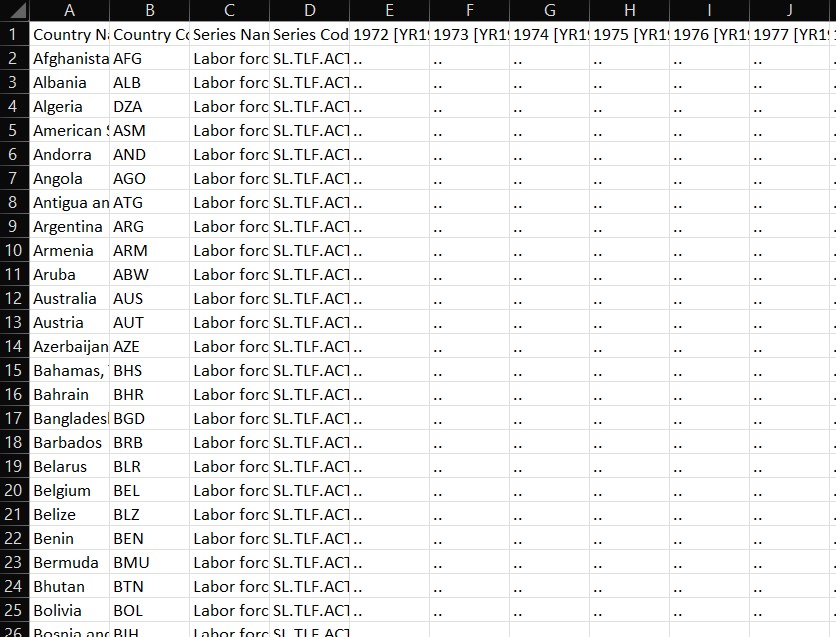
Read Data
Pivot the Data
- Use
pivot_longer()to get the data in long form - Use
pivot_wider()to get the series in the columns
Special Considerations
Special Considerations
Give it a Shot!
- Try downloading some messy WB data and make it tidy
- Refer to previous slides for help
10:00
Mutate
Mutating Variables
- Anytime we want to change a variable, we are going to use the
dplyrverbsmutate()ormutate_at() mutate()is if you want to change on variable- Use
across()for multiple variables
Let’s Fix Our Variables
Now Try it With Multiple Varaibles
- Go to the data frame with multiple variables that you created earlier
- How would you modify this code to make sure the variables are in the right format?
Clean Variable Names
Very simple: use the
janitor package!Column Specifications
- Can clean columns on backend
- But can also specify data types in
read_csv()orread_excel()