Linear Regression
June 22, 2025
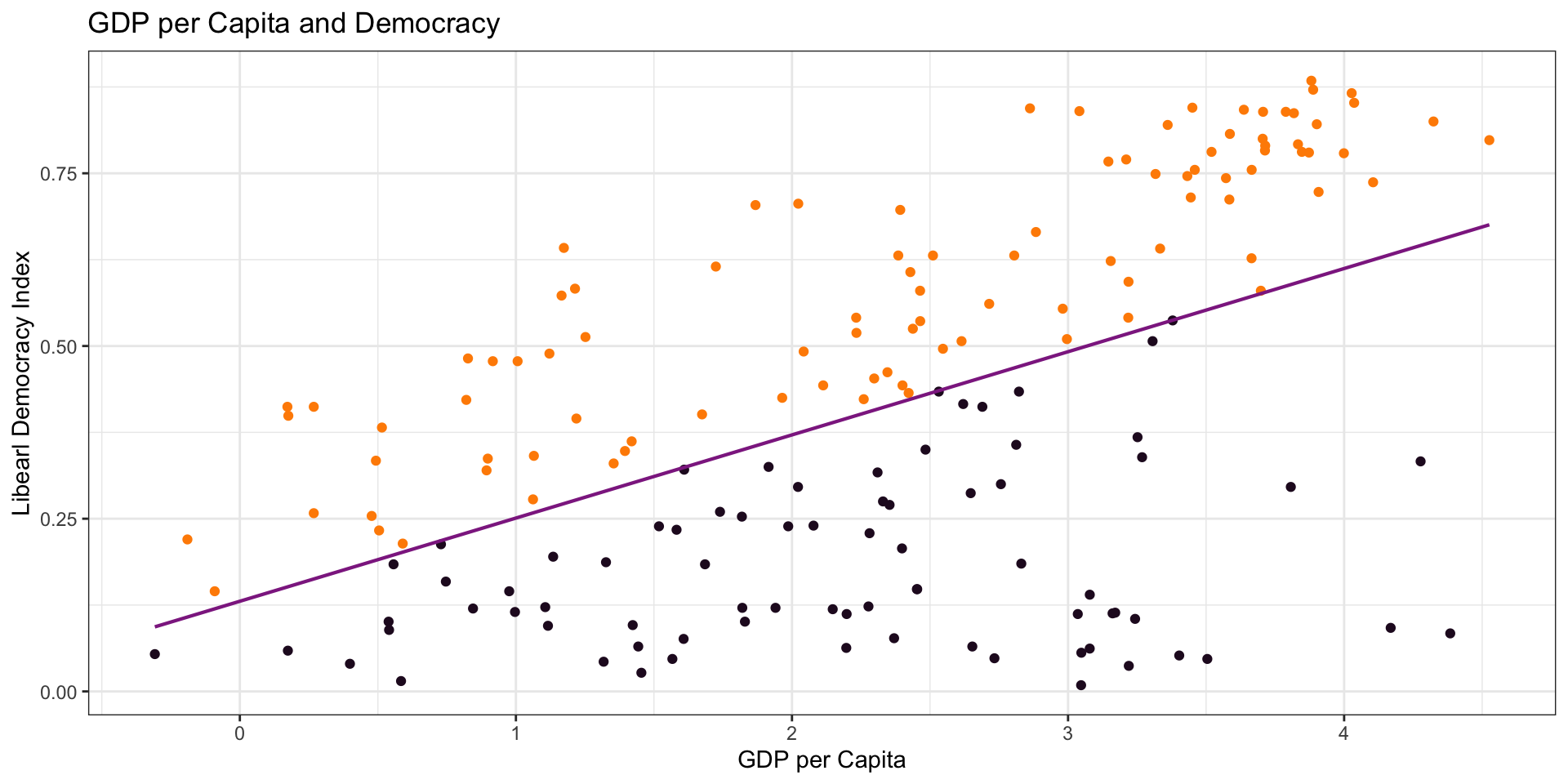
Modeling
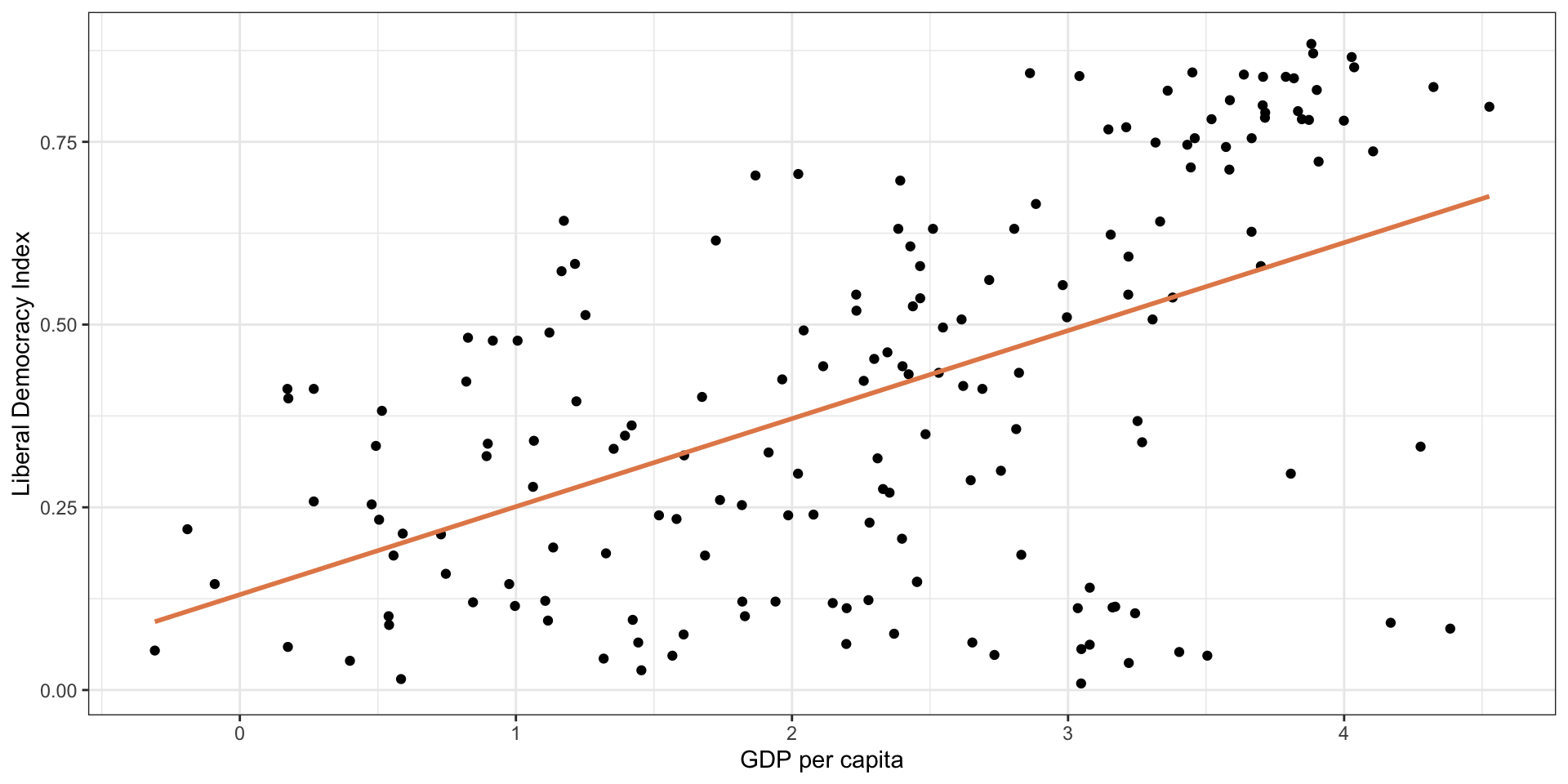
Modeling
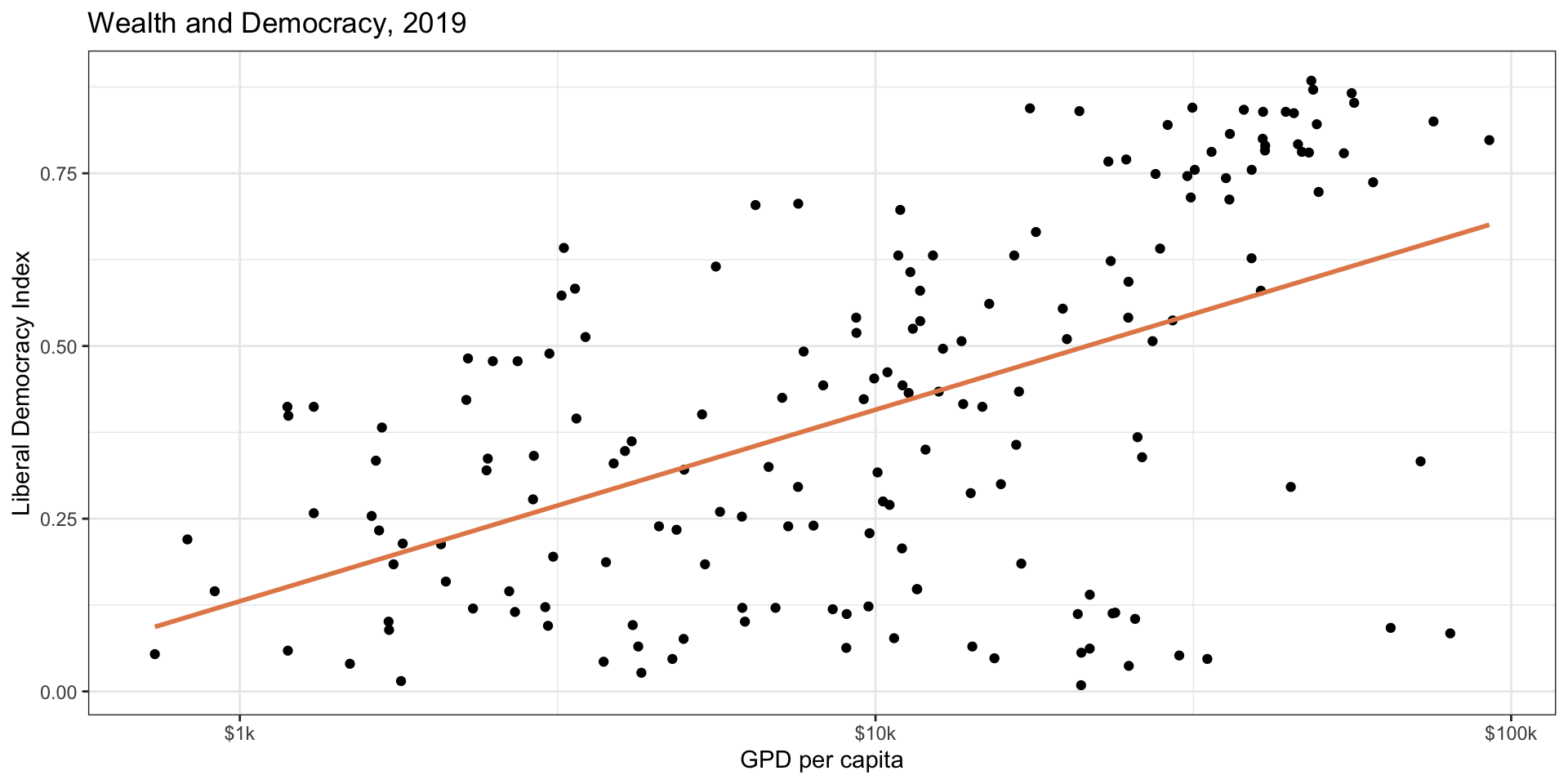
Plot the Data
Residuals
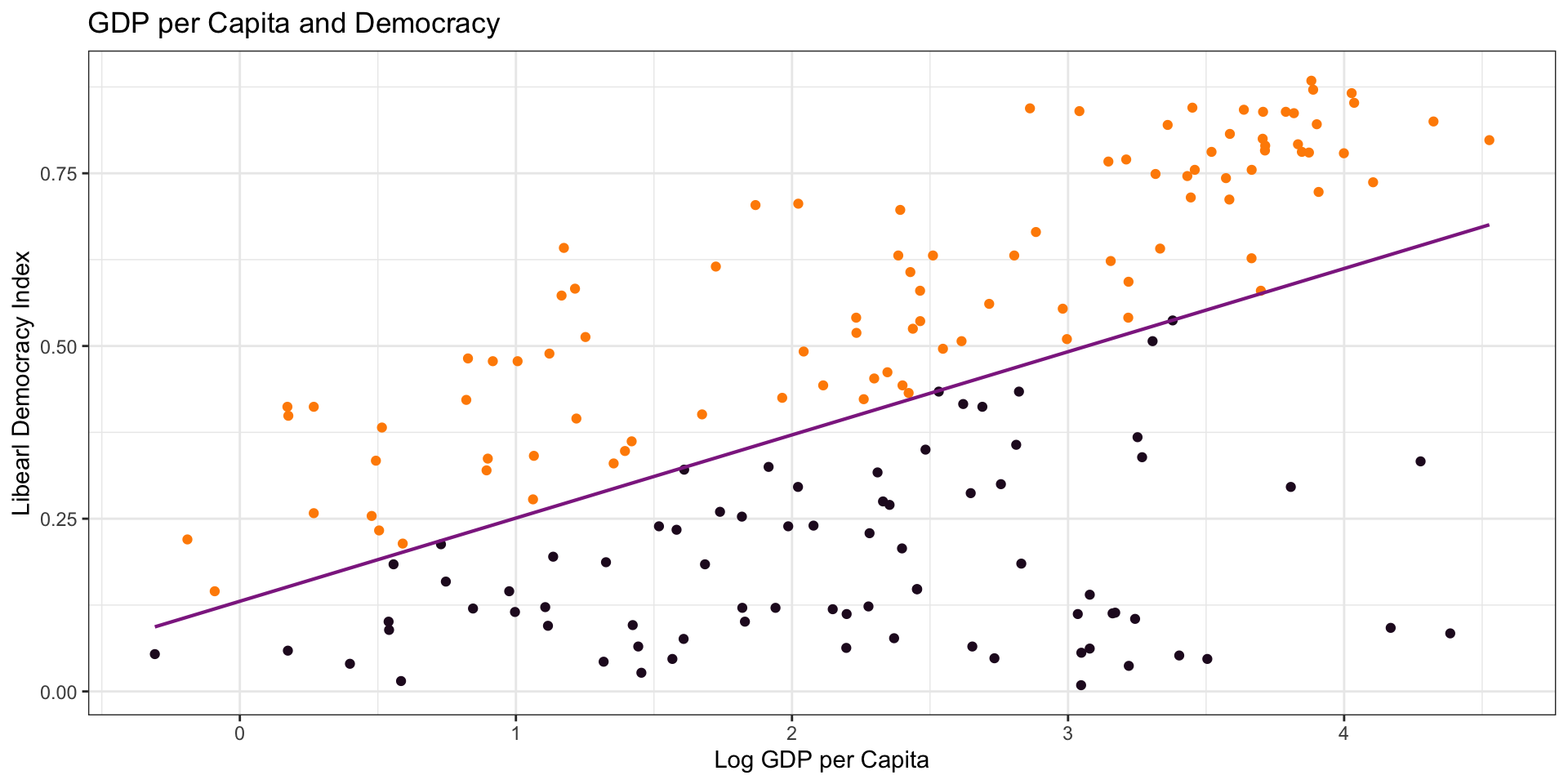
Linear Model
\(\hat{Y} = a + b \times X\)
\(\hat{Y} = 0.13 + 0.12 \times X\)
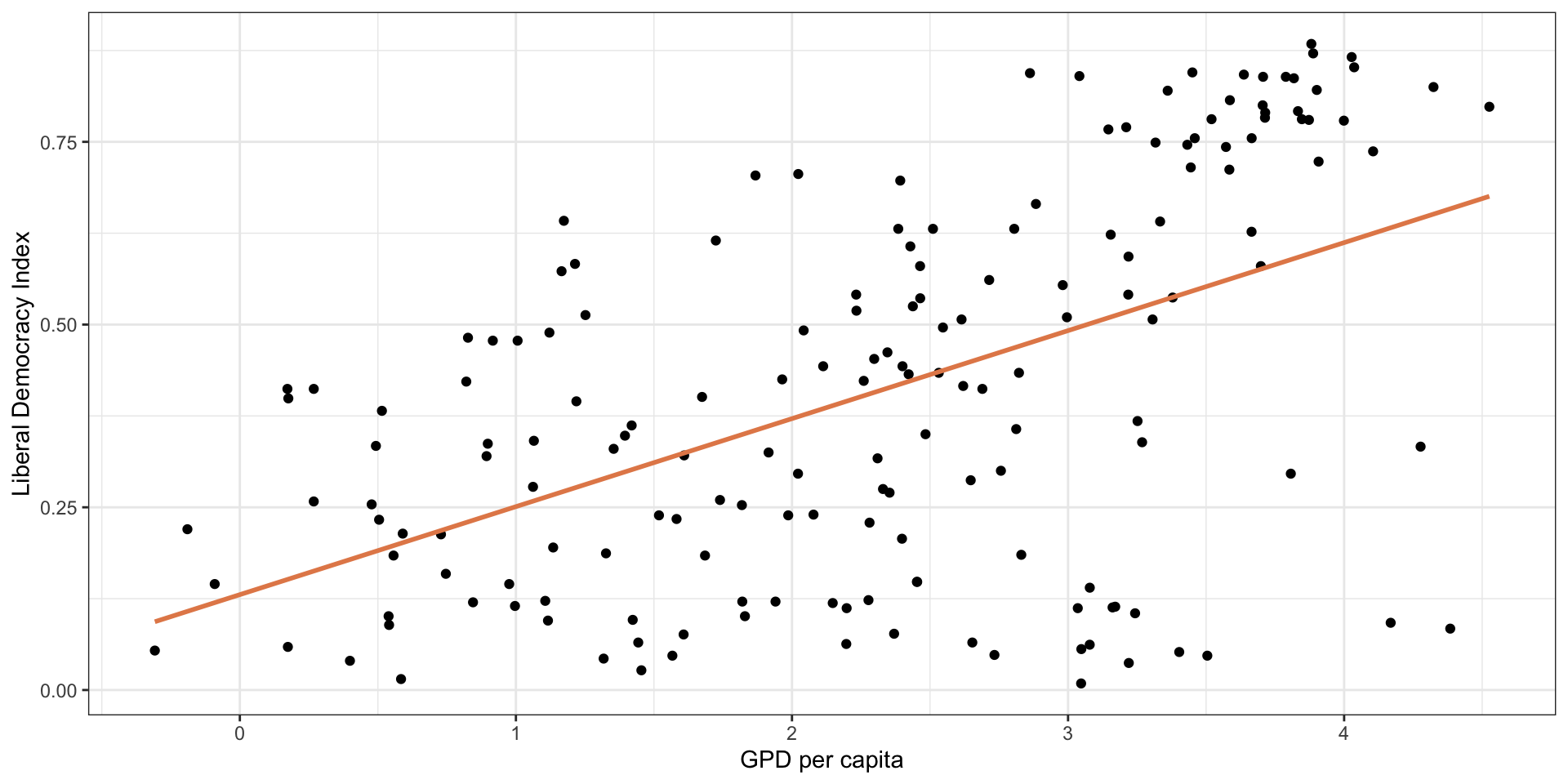
Linear Model: Interpretation
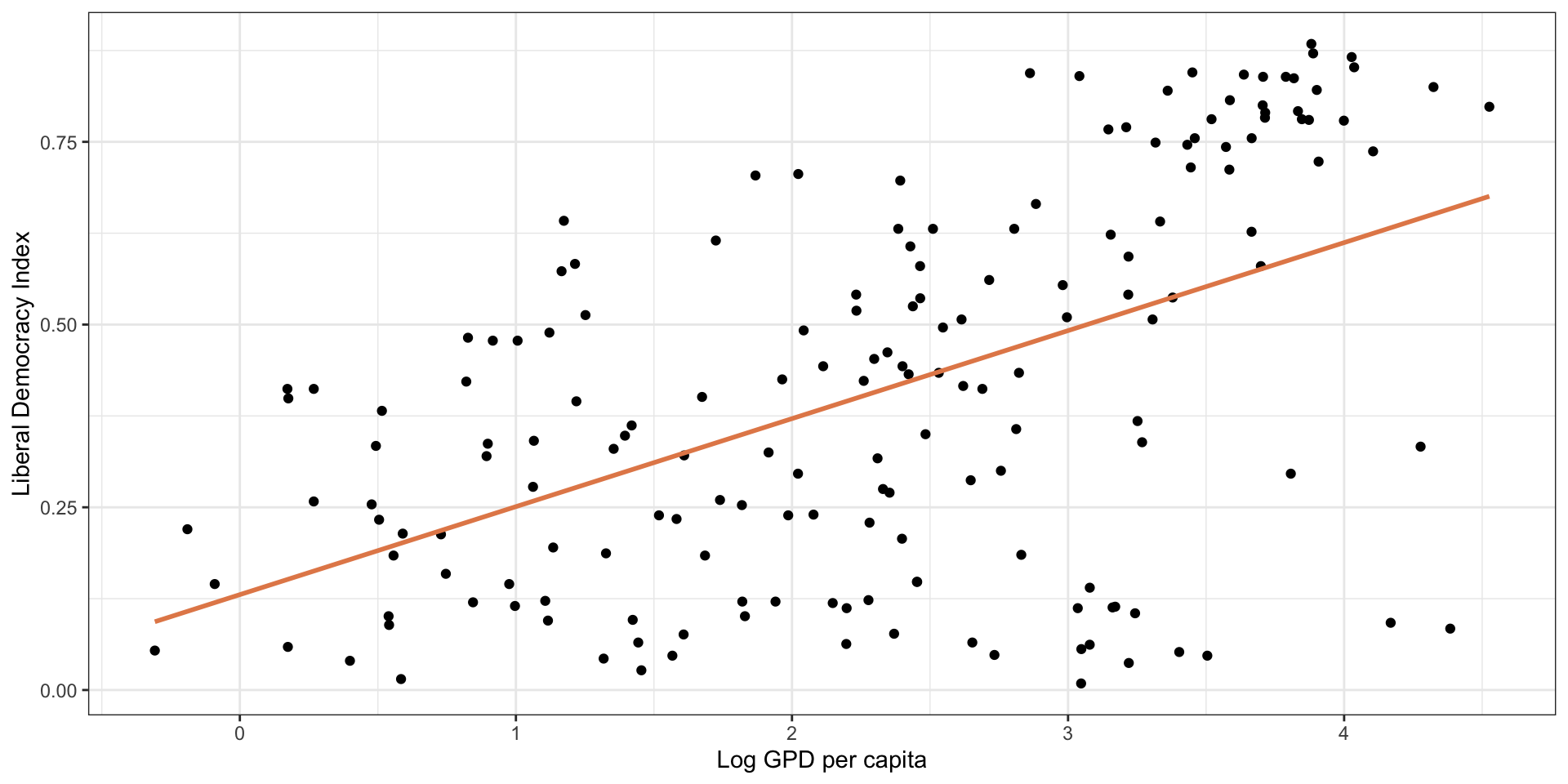
Linear Model: Interpretation
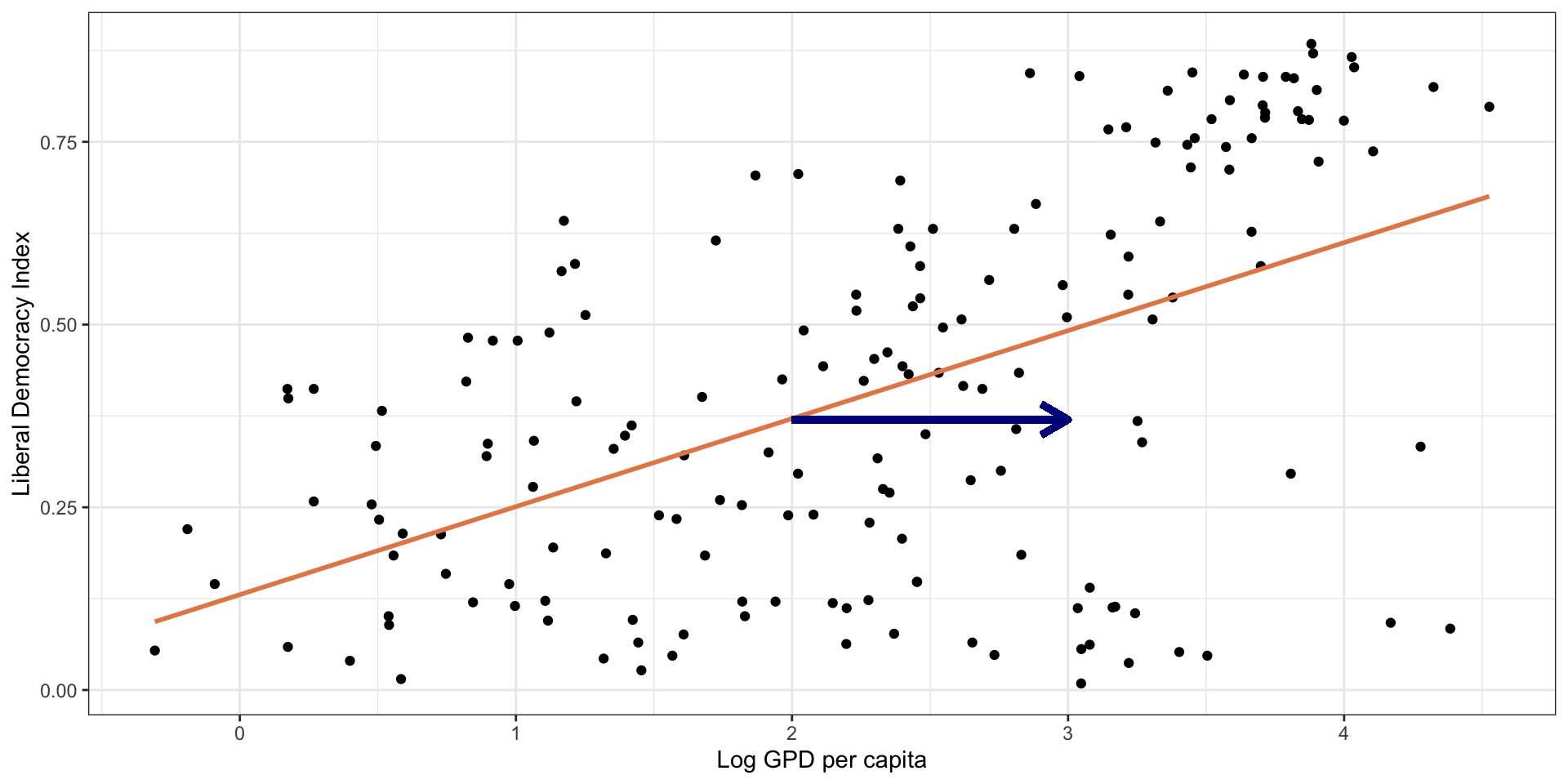
Linear Model: Interpretation
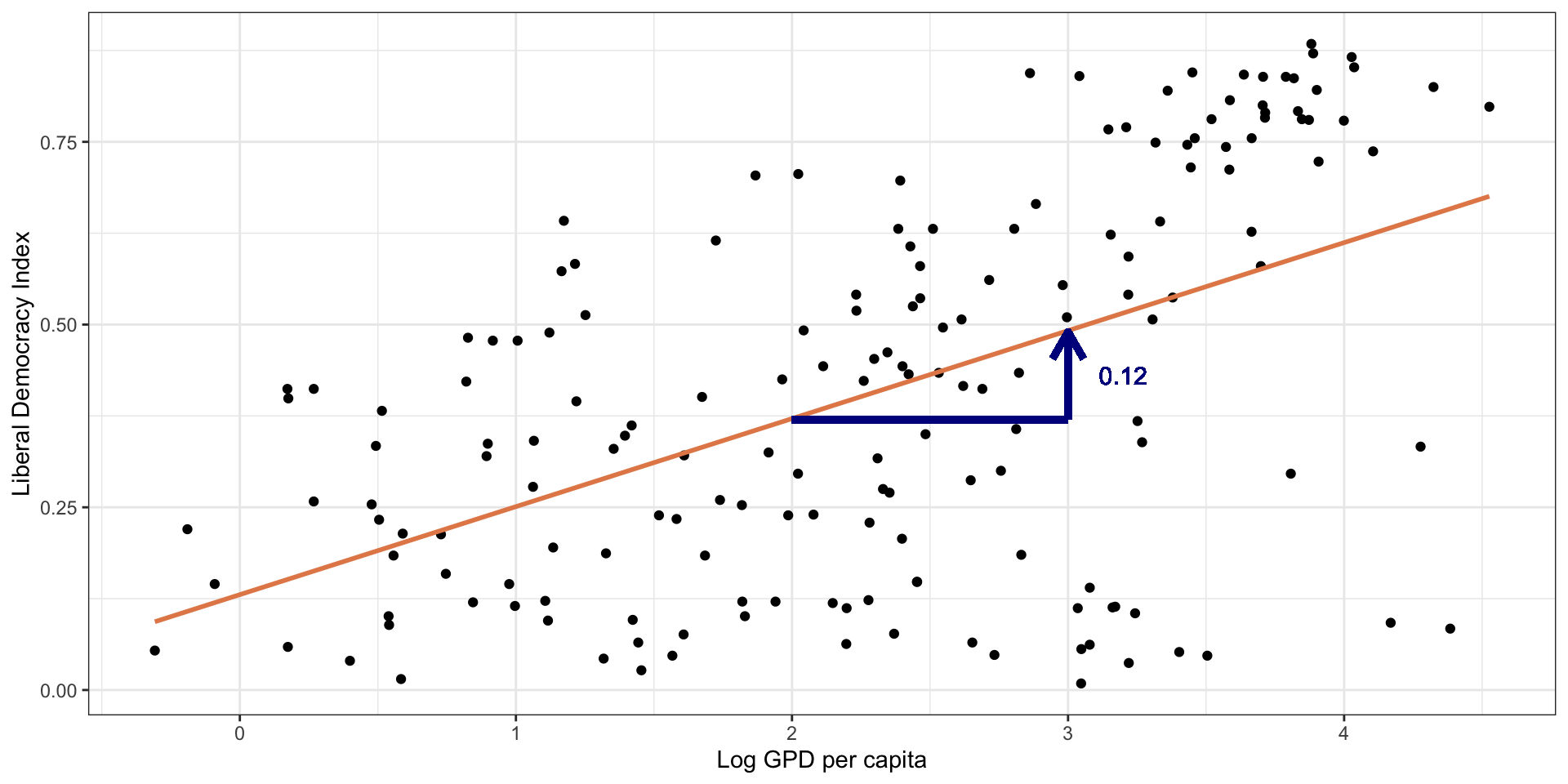
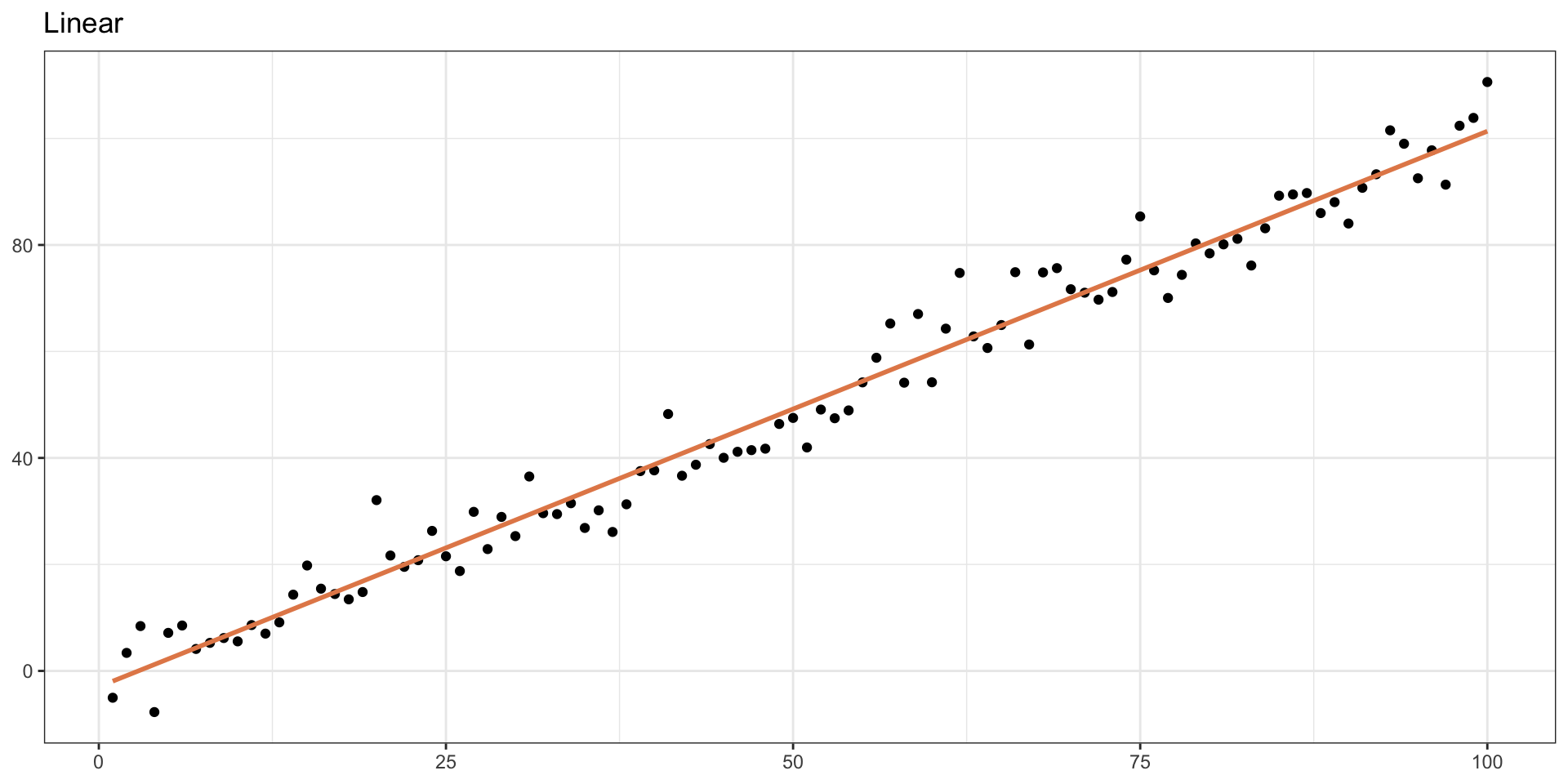
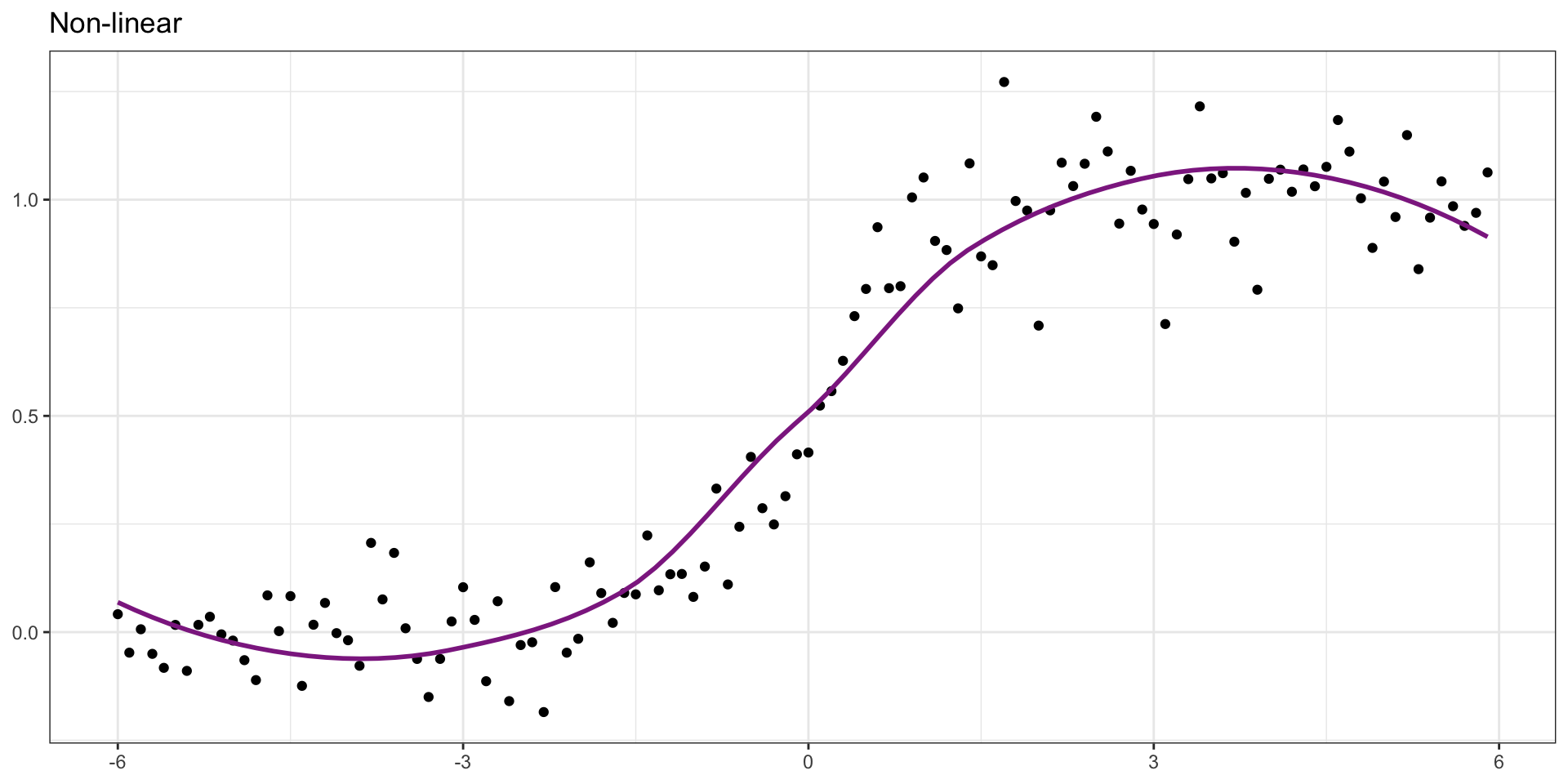
Linear Model with Single Predictor
How would you draw the “best” line?
How would you draw the “best” line?
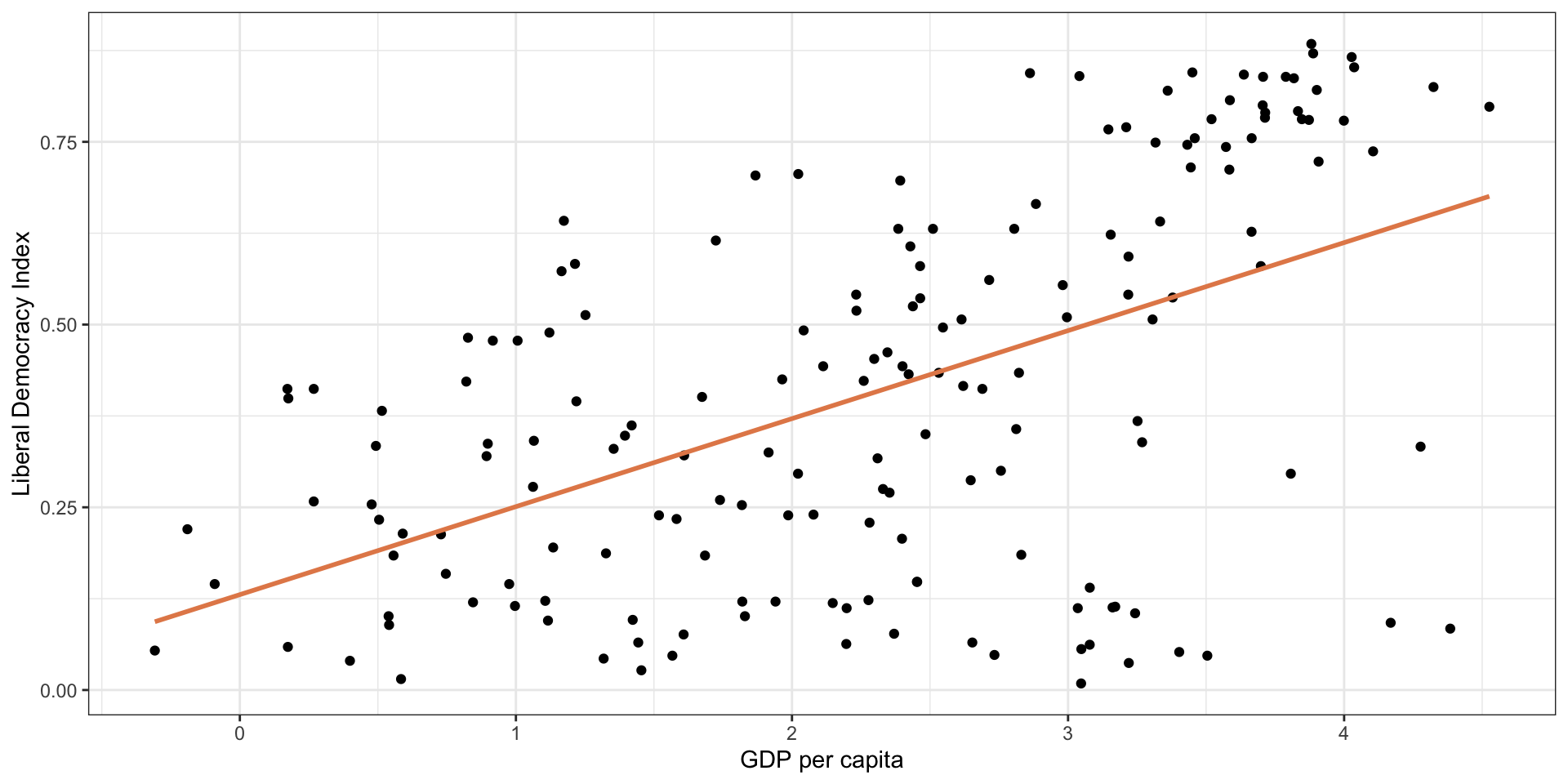
Least squares regression
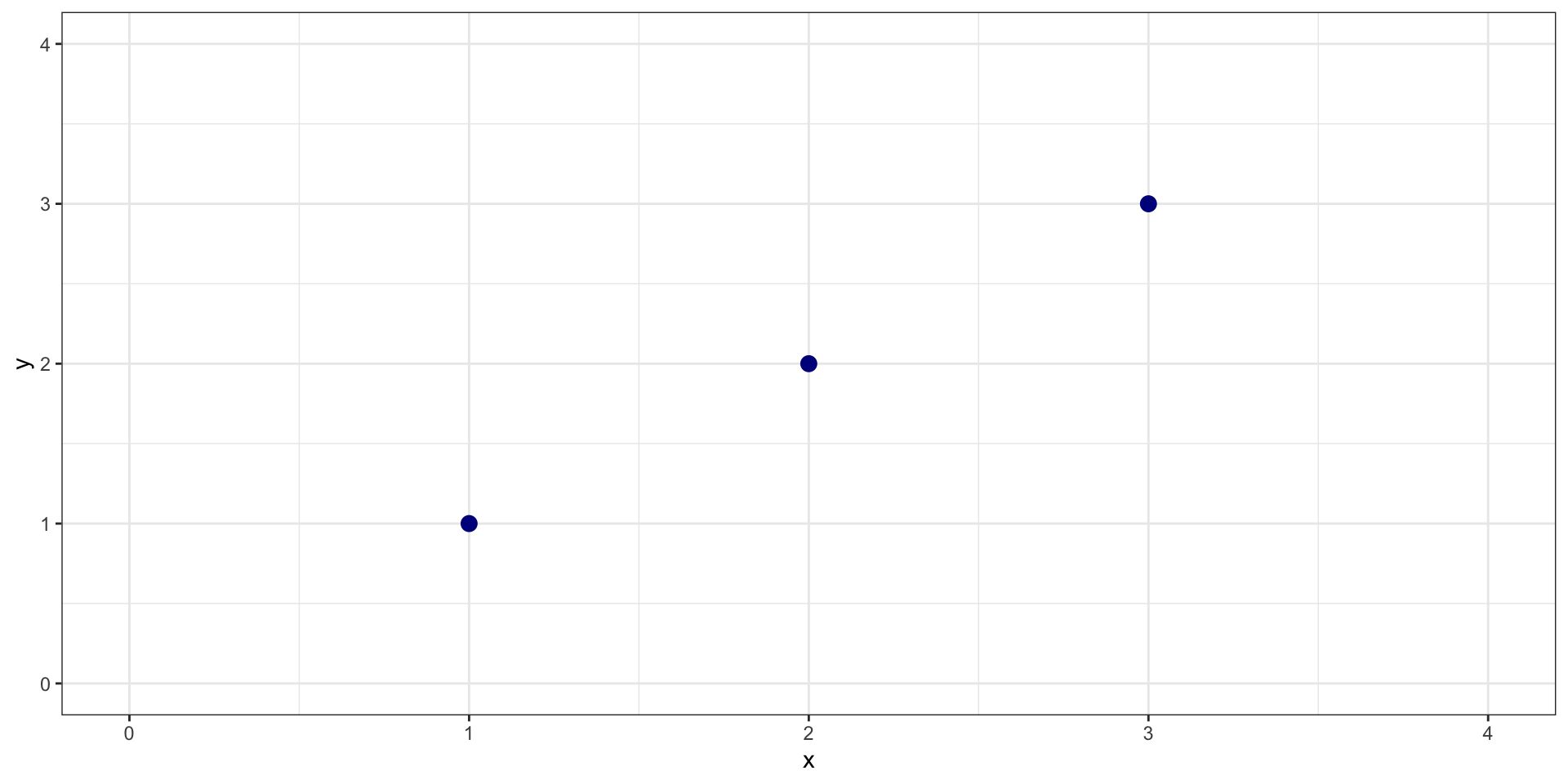
Very Simple Example
What should the slope and intercept be?
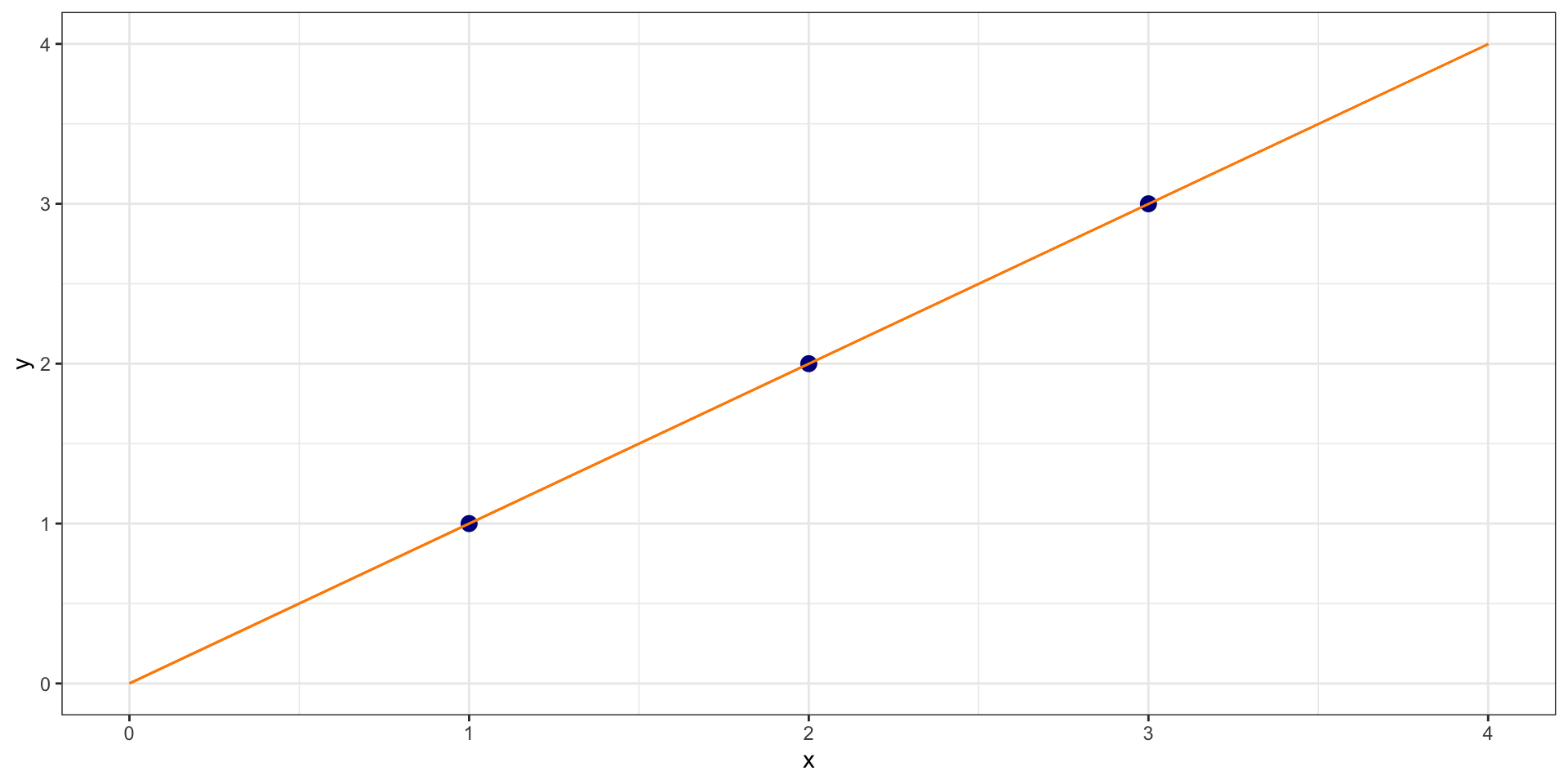
Example
\(\hat{Y} = 0 + 1*X\)
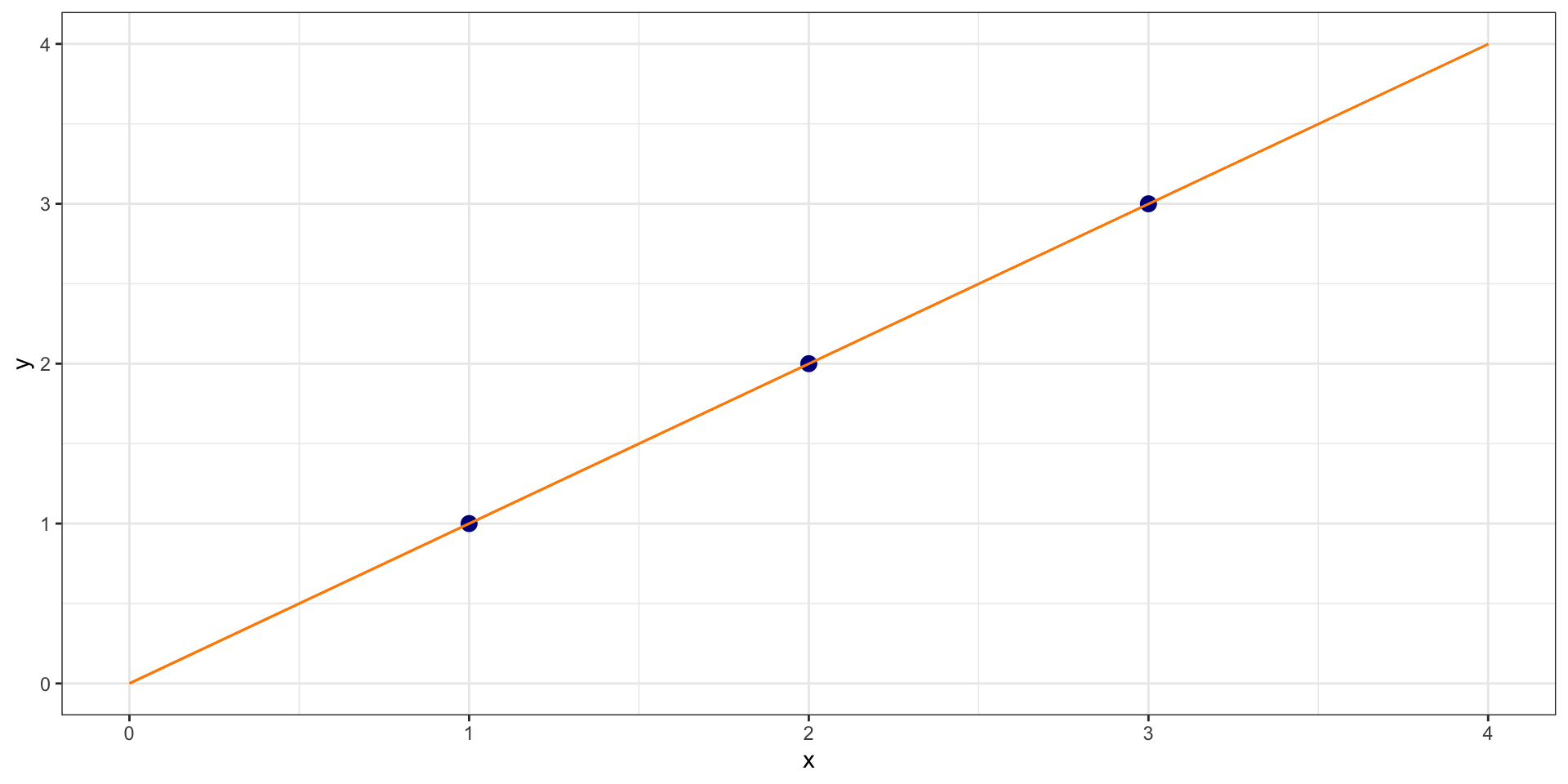
Example
What is the sum of squared residuals?
Example
What is sum of squared residuals for \(y = 0 + 0*X\)?
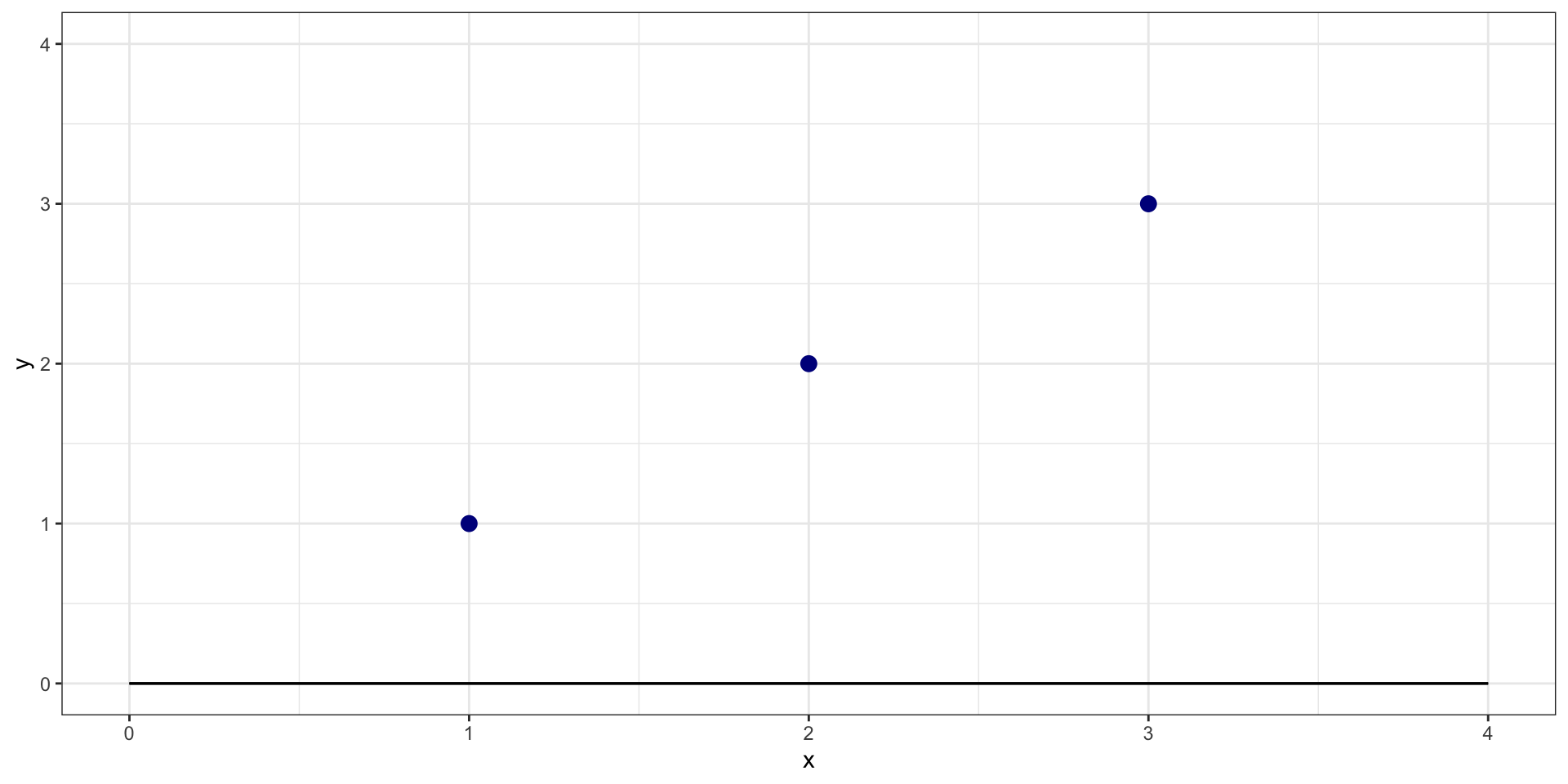
Example
What is sum of squared residuals for \(y = 0 + 0*X\)?
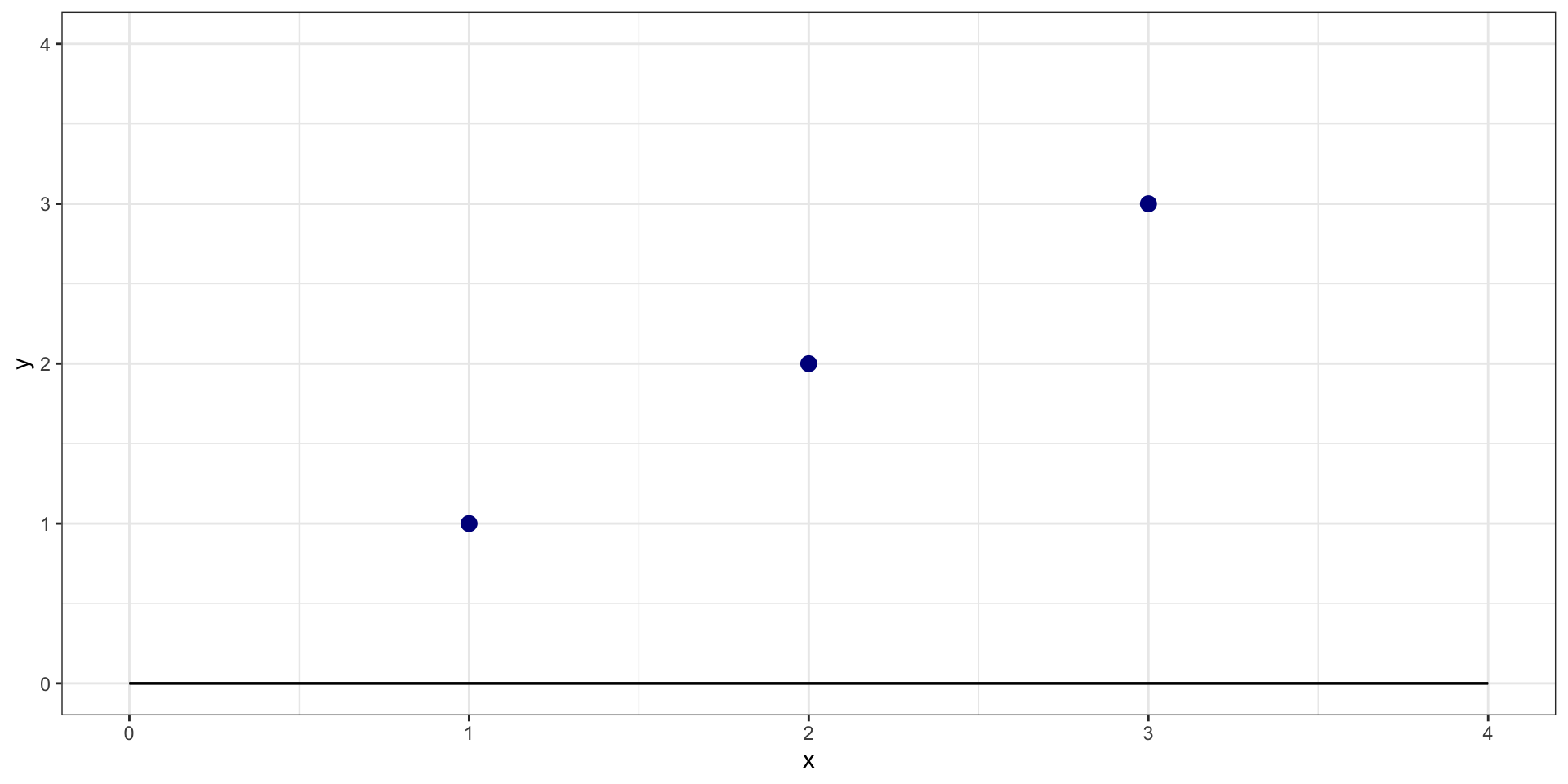
Example
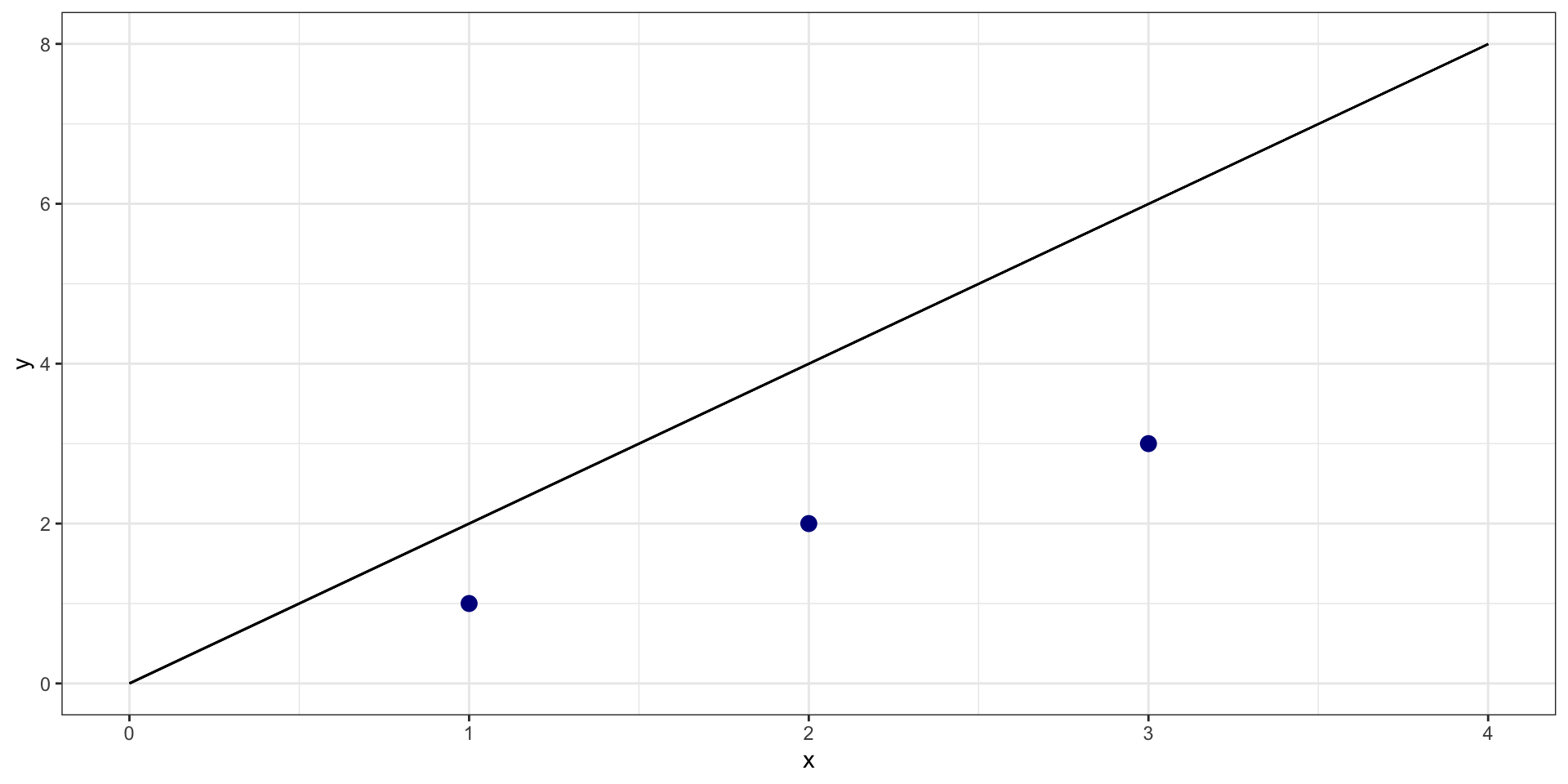
What is sum of squared residuals for \(y = 0 + 2*X\)?
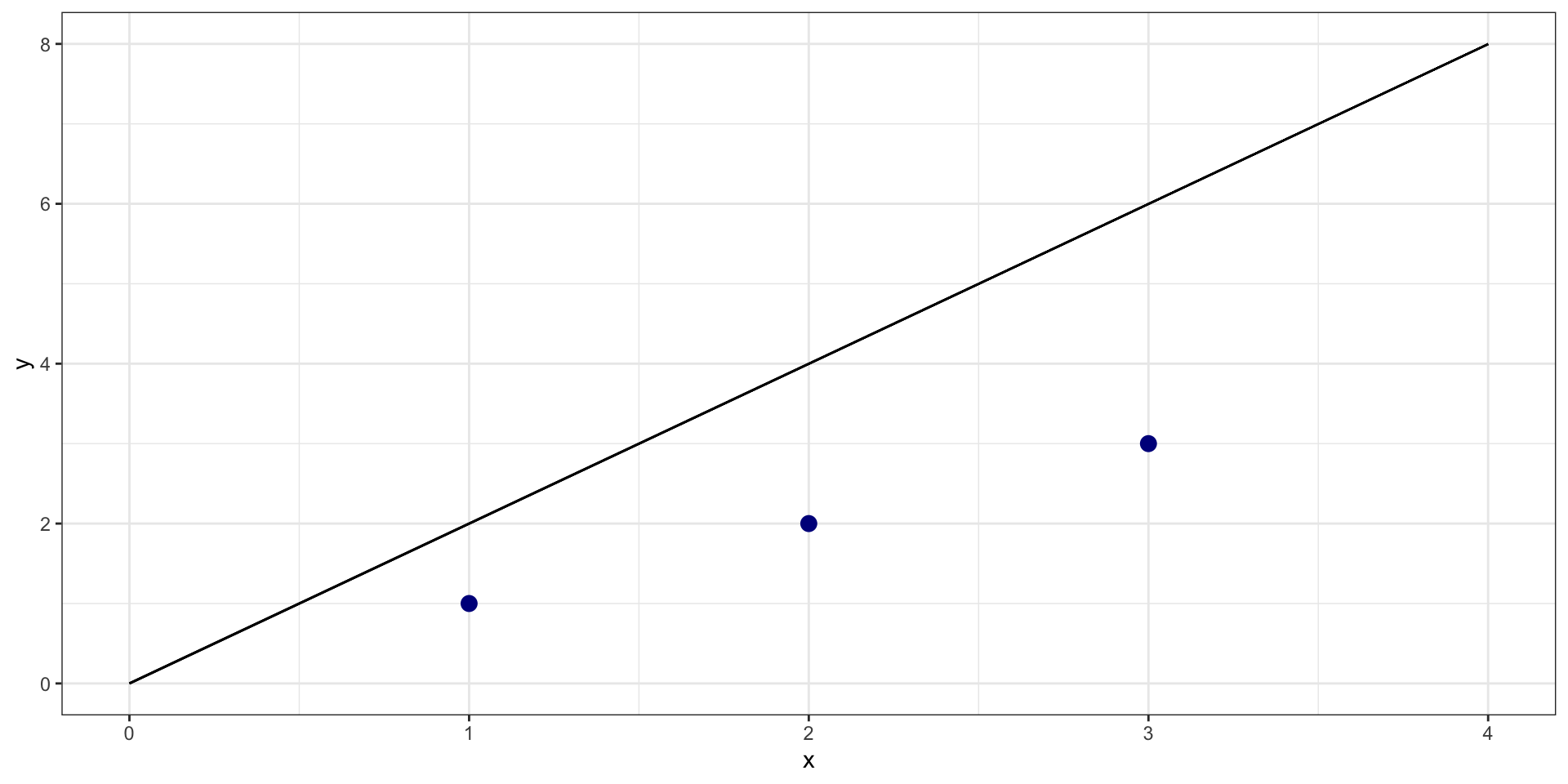
Example
What is sum of squared residuals for \(y = 0 + 2*X\)?
One more…
What is sum of squared residuals for \(y = 0 + -1*X\)?
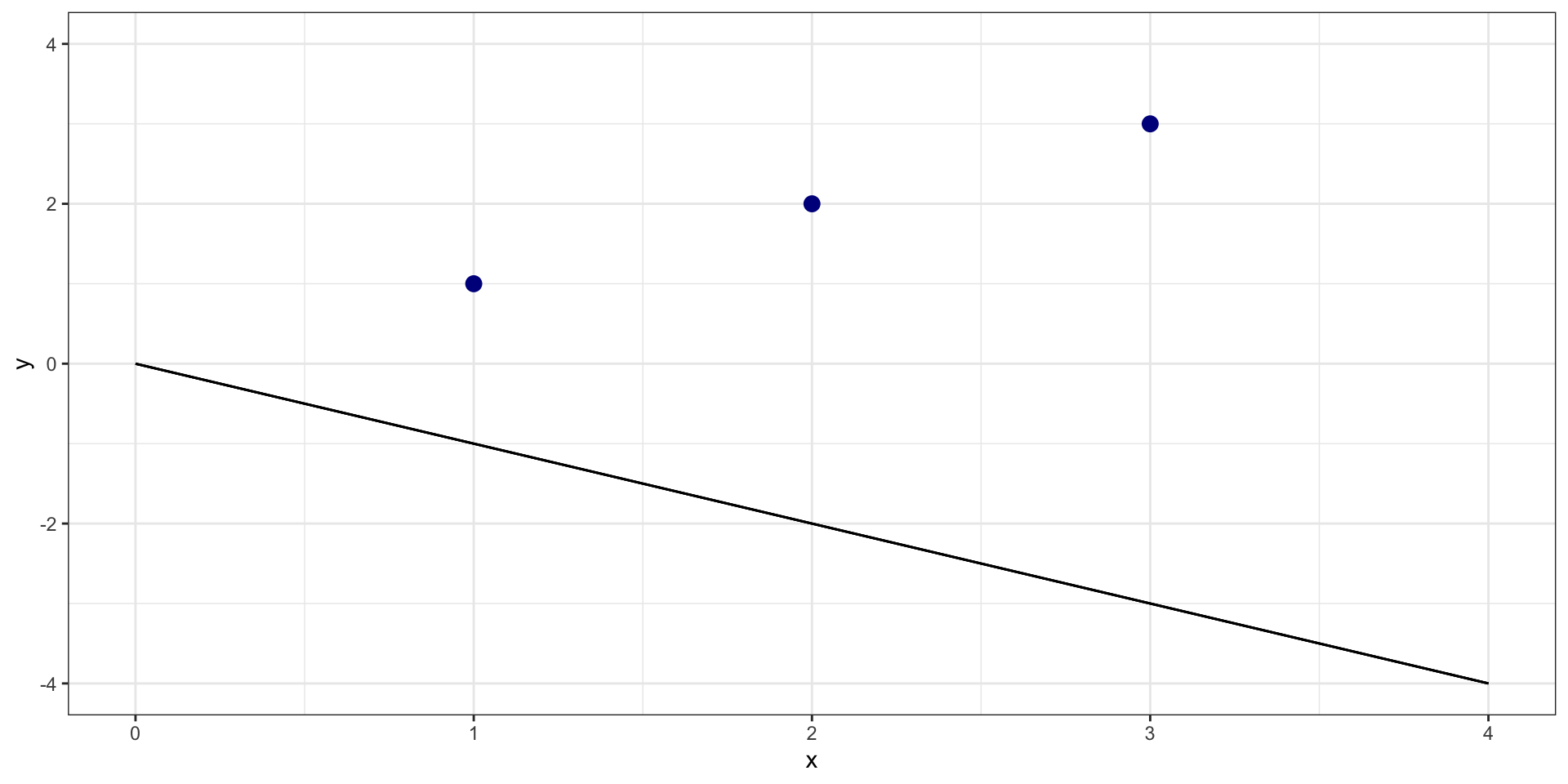
One more…
What is sum of squared residuals for \(y = 0 + -1*X\)?
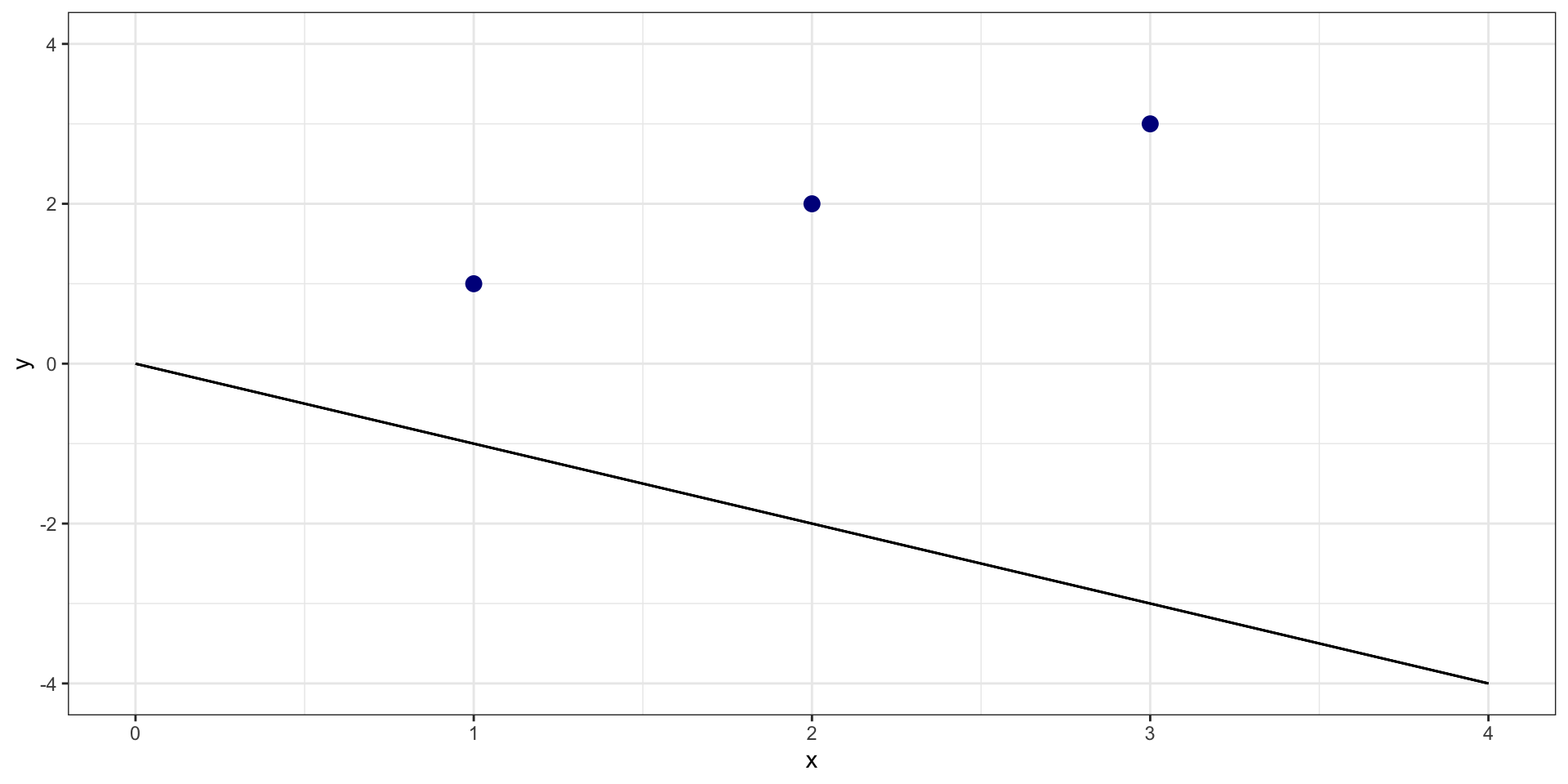
Cost Function
Sum of Squared Residuals as function of possible values of \(b\)
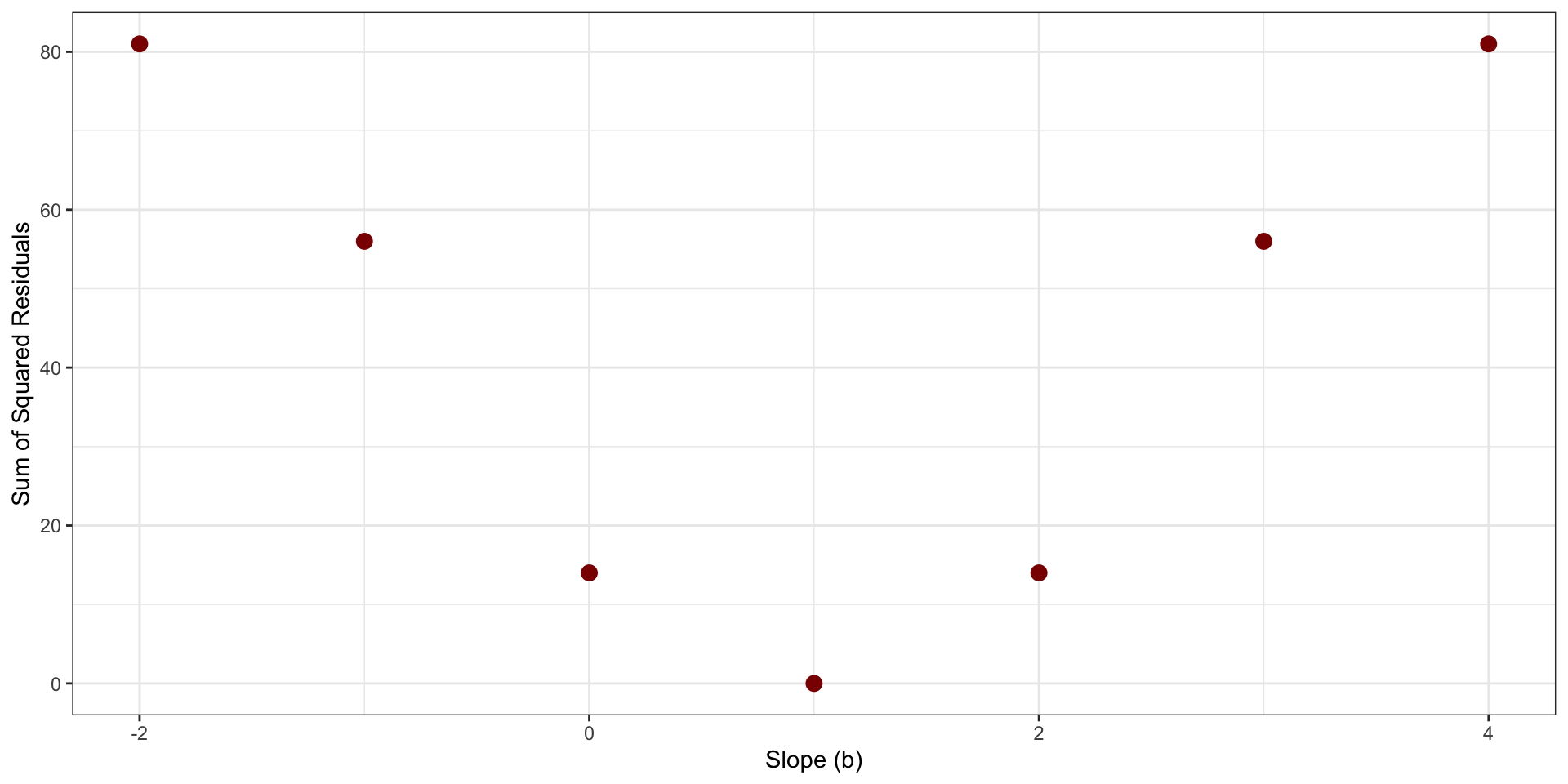
Least Squares Regression
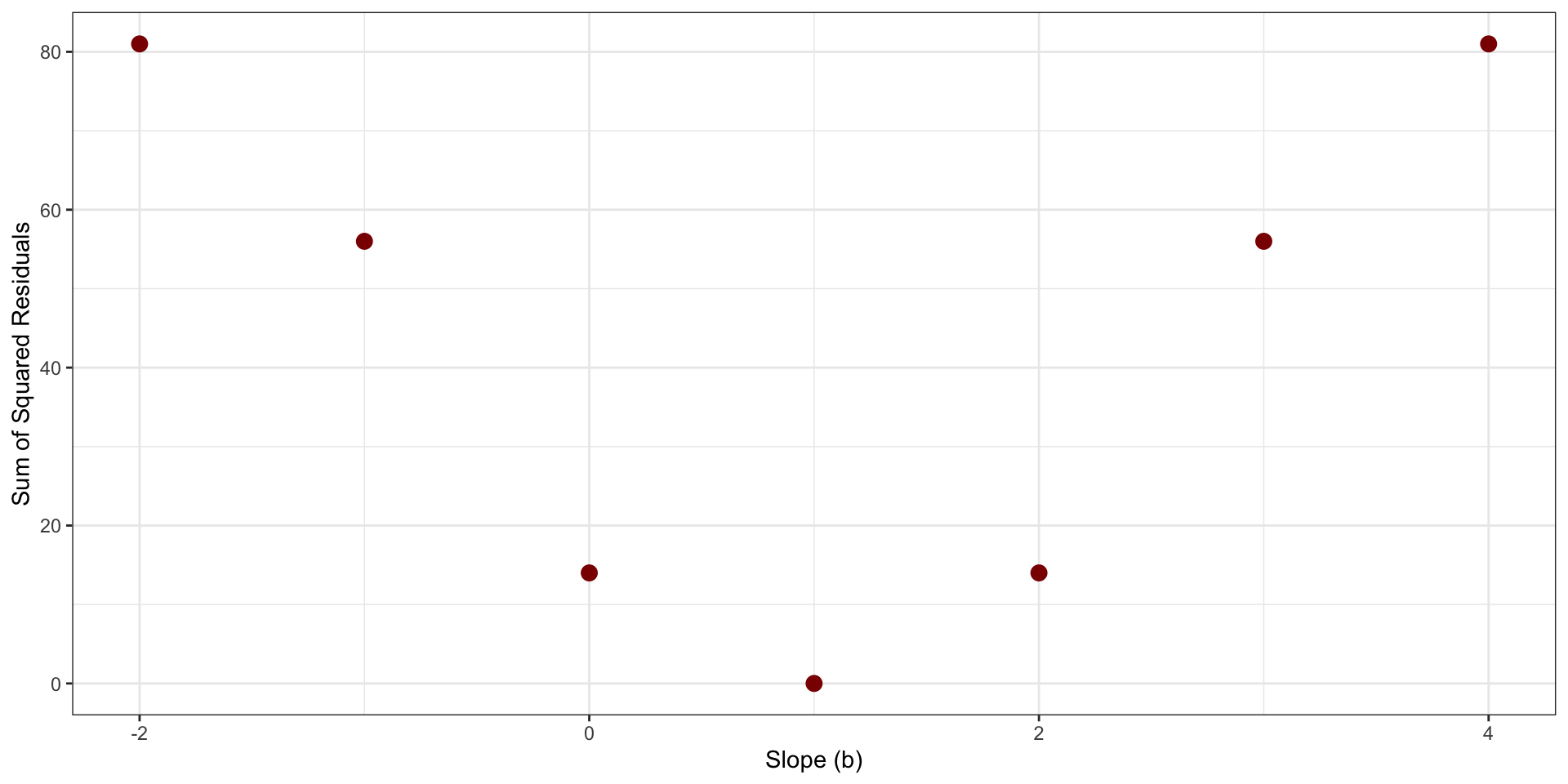
Least Squares Regression